Tracing 시리즈
서론
“이 API 왜 이렇게 느려요?” MSA 환경에서 이 질문에 답하려면, 요청이 어떤 서비스를 거쳐 어디서 시간을 소비했는지 추적해야 합니다. 서비스가 3개일 때는 로그를 뒤져가며 찾을 수 있지만, 수십 개의 서비스가 얽혀있다면? Distributed Tracing 없이는 사실상 불가능합니다.
이 글에서는 Distributed Tracing이 왜 필요한지, OpenTelemetry가 어떻게 업계 표준이 되었는지, 그리고 Spring Boot 생태계에서는 어떤 선택지가 있는지 정리합니다. 특히 Micrometer와 OpenTelemetry 중 무엇을 선택해야 하는지 헷갈리는 분들에게 명확한 기준을 제공하고자 합니다.
Distributed Tracing이 해결하는 문제
모놀리식 아키텍처에서는 하나의 요청이 하나의 프로세스 안에서 처리됩니다. 문제가 생기면 해당 서버의 로그를 보면 됩니다. 하지만 MSA 환경에서는 상황이 다릅니다.
사용자가 주문 버튼을 클릭하면 다음과 같은 흐름이 발생할 수 있습니다:

이 중 어딘가에서 지연이 발생했다면, 어떻게 찾을까요? 각 서비스의 로그를 시간대별로 맞춰가며 추적하는 건 비현실적입니다. 요청마다 고유한 ID를 부여하고, 이 ID가 모든 서비스를 따라다니게 하면 어떨까요? 이것이 Distributed Tracing의 핵심 아이디어입니다.
Trace: 하나의 요청이 시스템을 통과하는 전체 여정
Span: 그 여정에서 각 작업 단위 (예: HTTP 요청 처리, DB 쿼리 실행)
Trace ID: 전체 여정을 식별하는 고유 ID
Span ID: 각 작업 단위를 식별하는 ID
Observability의 세 기둥, 그리고 통합의 필요성
시스템을 관찰하는 데이터는 크게 세 가지로 분류됩니다.
Metrics는 시스템의 상태를 숫자로 표현합니다. CPU 사용률, 메모리 사용량, 요청 처리량, 평균 응답 시간 같은 것들이죠. 시계열 데이터베이스에 저장되어 대시보드로 시각화됩니다. Prometheus와 Grafana 조합이 대표적입니다.
Logging은 이벤트의 기록입니다. 특정 시점에 무슨 일이 있었는지를 텍스트로 남깁니다. ELK Stack(Elasticsearch, Logstash, Kibana)이 오랫동안 표준처럼 사용되어 왔습니다.
Tracing은 요청의 여정을 추적합니다. 분산 시스템에서 하나의 요청이 어떤 경로로 흘러갔는지, 각 구간에서 얼마나 시간이 걸렸는지를 보여줍니다. Zipkin, Jaeger가 대표적인 도구입니다.
분리된 세계의 한계
문제는 이 세 가지가 오랫동안 따로 발전해왔다는 점입니다.
대시보드에서 갑자기 에러율이 치솟는 걸 발견했다고 가정해봅시다. Metrics가 알려주는 건 “에러가 많이 발생하고 있다”는 사실뿐입니다. 어떤 요청에서 에러가 났는지, 그 요청이 어떤 경로를 거쳤는지는 알 수 없습니다. 로그를 뒤져야 하는데, 에러가 발생한 시간대의 로그가 수만 건이라면? 그중에서 문제의 요청을 찾는 건 사막에서 바늘 찾기입니다.
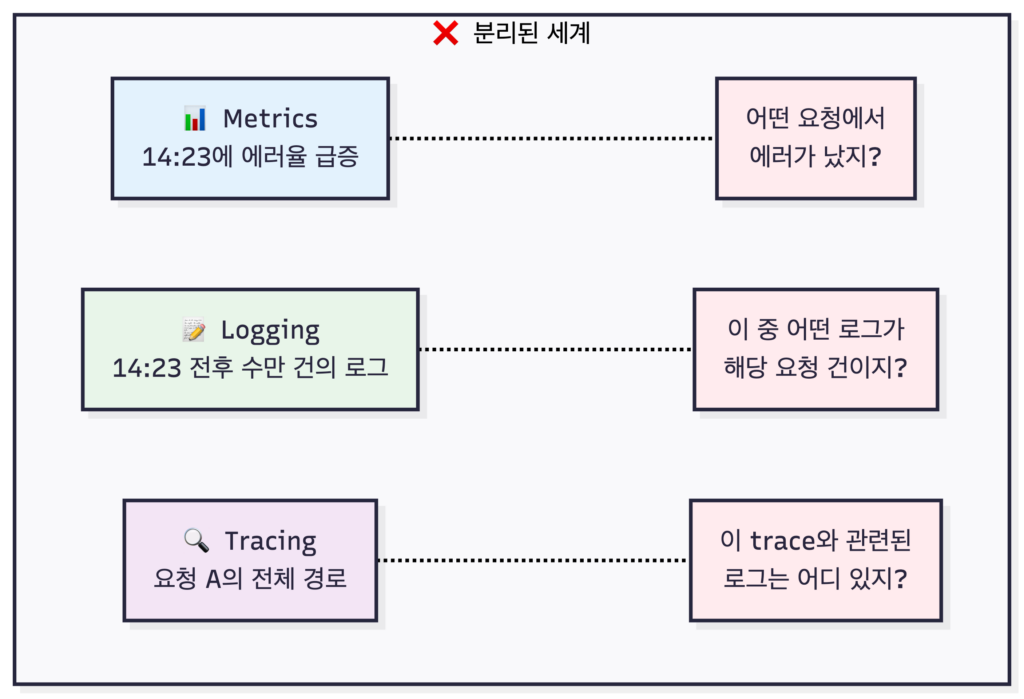
세 가지 데이터가 서로 연결되지 않으니, 문제 해결에 필요한 정보를 모으는 것 자체가 일입니다.
Trace ID로 연결하기
해결책은 의외로 단순합니다. 모든 데이터에 동일한 식별자를 붙이면 됩니다.
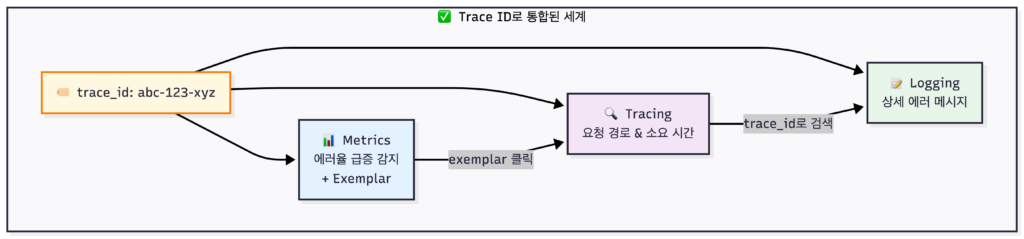
Tracing에서는 당연히 Trace ID가 있습니다. 이건 원래부터 그랬습니다.
[Trace]
trace_id: abc-123-xyz
spans:
- service: order-service, duration: 45ms
- service: payment-service, duration: 120msCode language: CSS (css)Logging에 Trace ID를 추가합니다. 로그를 남길 때 현재 처리 중인 요청의 Trace ID를 함께 기록합니다.
2024-01-15 14:23:45 [trace_id=abc-123-xyz span_id=def-456] ERROR PaymentService - Insufficient funds
2024-01-15 14:23:45 [trace_id=abc-123-xyz span_id=ghi-789] INFO OrderService - Payment failed, rolling backCode language: CSS (css)이제 Trace ID로 검색하면 해당 요청과 관련된 모든 로그를 한 번에 볼 수 있습니다.
이 기능의 핵심에는 MDC(Mapped Diagnostic Context)가 있습니다. MDC는 현재 스레드에 연결된 컨텍스트 정보를 저장하는 공간입니다. Tracing 라이브러리가 요청을 처리할 때 Trace ID를 MDC에 넣어두면, 로깅 프레임워크(Logback, Log4j)가 로그를 출력할 때 자동으로 이 값을 포함시킵니다. MDC가 어떻게 동작하는지, ThreadLocal과는 어떤 관계인지는 다음편에서 자세히 다룹니다.
Metrics에도 Trace ID를 연결합니다. 이건 조금 다른 방식으로 동작합니다. 모든 메트릭 데이터 포인트에 Trace ID를 붙이면 데이터가 폭발하니까요. 대신 Exemplar라는 개념을 사용합니다.
http_request_duration_seconds{service="payment"} 2.1 # {trace_id="abc-123-xyz"} 4.3Code language: PHP (php)이 메트릭의 의미를 풀어보면:
| 구성 요소 | 값 | 의미 |
|---|---|---|
| 메트릭 이름 | http_request_duration_seconds | HTTP 요청 응답 시간 |
| 라벨 | {service="payment"} | payment 서비스의 메트릭 |
| 집계 값 | 2.1 | 전체 요청들의 평균 응답 시간 |
| Exemplar trace_id | abc-123-xyz | 샘플로 첨부된 요청의 Trace ID |
| Exemplar 값 | 4.3 | 해당 샘플 요청의 실제 응답 시간 |
Grafana에서 응답 시간 그래프를 보다가 특이점을 클릭하면, Exemplar에 담긴 trace_id를 통해 해당 시점의 실제 요청 Trace로 바로 이동할 수 있습니다. “평균이 2.1초인데, 그중 4.3초짜리 느린 요청 하나를 샘플로 첨부해둘게. 궁금하면 이 trace를 봐”라는 개념입니다.
하나의 Trace ID로 세 가지 데이터를 연결하면, “대시보드에서 이상 징후 발견 → 문제 원인 파악”까지의 시간이 획기적으로 줄어듭니다.
💡 OpenTelemetry의 역할
OpenTelemetry는 이 통합을 “프로토콜 수준에서” 표준화합니다. Trace, Log, Metric 데이터 모델에 Trace ID, Span ID 필드를 포함하도록 정의하고, SDK에서 자동으로 이 값들을 채워넣도록 구현되어 있습니다. 그래서 OpenTelemetry를 사용하면 별도 설정 없이도 세 가지 데이터가 자연스럽게 연결됩니다.
Tracing 표준의 역사: B3에서 W3C Trace Context까지
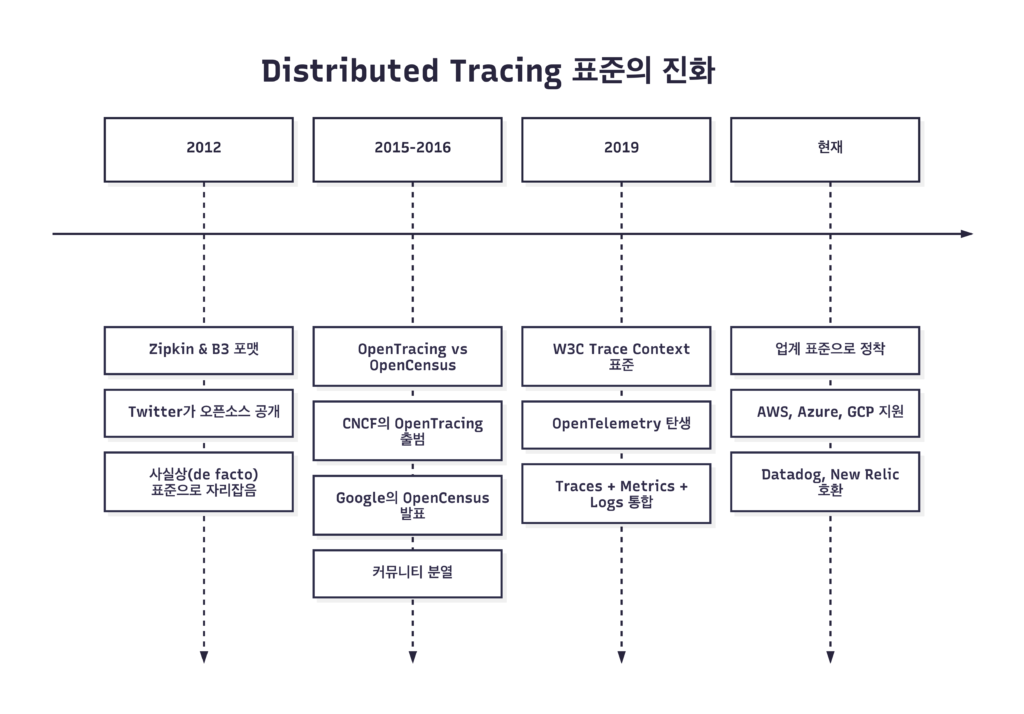
Distributed Tracing이 필요하다는 건 모두가 알았지만, 어떻게 구현할지는 제각각이었습니다.
Zipkin과 B3 포맷
2012년 Twitter가 Zipkin을 오픈소스로 공개했습니다. Google의 Dapper 논문에서 영감을 받은 이 프로젝트는 Distributed Tracing의 대중화를 이끌었습니다.
Zipkin은 B3라는 전파(propagation) 포맷을 사용했습니다. HTTP 요청의 헤더에 다음과 같은 정보를 담아 서비스 간에 전달하는 방식입니다.
X-B3-TraceId: 463ac35c9f6413ad48485a3953bb6124
X-B3-SpanId: 0020000000000001
X-B3-ParentSpanId: 0010000000000001
X-B3-Sampled: 1Code language: HTTP (http)각 필드의 의미:
| 헤더 | 의미 |
|---|---|
X-B3-TraceId | 전체 요청 여정의 고유 ID |
X-B3-SpanId | 현재 서비스에서의 작업 단위 ID |
X-B3-ParentSpanId | 나를 호출한 부모 Span의 ID (누가 나를 불렀는지) |
X-B3-Sampled | 이 요청을 수집할지 여부 (1 = 수집, 0 = 미수집) |
B3는 단순하고 이해하기 쉬웠습니다. 많은 프로젝트들이 B3를 채택했고, 사실상의(de facto) 표준처럼 자리 잡았습니다. 하지만 공식 표준은 아니었기에, 미묘하게 다른 구현들이 생겨났습니다. Single header 방식과 multi-header 방식이 혼재했고, 128비트 vs 64비트 Trace ID 처리도 제각각이었습니다.
분열의 시대: OpenTracing vs OpenCensus
2015년, Tracing API를 표준화하려는 시도가 시작됩니다. CNCF(Cloud Native Computing Foundation)에서 OpenTracing 프로젝트가 출범했습니다. 벤더 중립적인 API를 제공해서, 애플리케이션 코드를 수정하지 않고도 백엔드 트레이싱 시스템을 교체할 수 있게 하자는 목표였습니다.
거의 비슷한 시기에 Google은 OpenCensus를 발표합니다. OpenTracing이 Tracing API만 정의한 데 비해, OpenCensus는 Tracing과 Metrics를 모두 다뤘습니다. 또한 API 정의뿐 아니라 SDK 구현체까지 제공했습니다.
두 프로젝트 모두 좋은 의도를 가졌지만, 결과적으로 커뮤니티가 분열됐습니다. 어떤 라이브러리는 OpenTracing을 지원하고, 어떤 라이브러리는 OpenCensus를 지원했습니다. 둘 다 지원하는 경우도 있었지만, 개발자 입장에서는 혼란스러웠습니다.
OpenTelemetry의 등장
2019년, 두 프로젝트가 합병하여 OpenTelemetry(OTel)가 탄생합니다.
OpenTelemetry는 세 가지를 모두 아우릅니다:
- Traces: 분산 추적
- Metrics: 메트릭 수집
- Logs: 로그 수집 (나중에 추가됨)
또한 W3C에서 정의한 Trace Context 표준을 기본 전파 포맷으로 채택했습니다.
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
tracestate: vendor1=value1,vendor2=value2Code language: HTTP (http)traceparent 헤더 하나에 버전, Trace ID, Span ID, 플래그가 모두 담깁니다. tracestate는 벤더별 추가 정보를 담을 수 있는 확장 포인트입니다.
traceparent의 구조를 분해하면:
00: 버전 (현재 버전 00)0af7651916cd43dd8448eb211c80319c: Trace ID (128비트, 32자 hex)b7ad6b7169203331: Span ID (64비트, 16자 hex)01: 플래그 (01 = sampled)
B3와 W3C Trace Context 변환
두 포맷은 담고 있는 정보가 유사하기 때문에 상호 변환이 가능합니다.
| 구성 요소 | B3 Multi-Header | W3C Trace Context |
|---|---|---|
| Trace ID | X-B3-TraceId: | traceparent의 2번째 필드 |
| Span ID | X-B3-SpanId: | traceparent의 3번째 필드 |
| Parent Span ID | X-B3-ParentSpanId: | ❌ 헤더에 없음 (이유는 아래에서 설명) |
| Sampled | X-B3-Sampled: 1 | traceparent의 4번째 필드 (01) |
💡 ParentSpanId는 어디로 갔나?
W3C Trace Context에는
ParentSpanId필드가 없습니다. 동작 방식이 다르기 때문입니다.B3 방식: ParentSpanId를 명시적으로 헤더에 담아 전달
W3C 방식:
traceparent에 있는 SpanId가 수신 측에서 자동으로 parent가 됨Service A가 Service B를 호출할 때: [A가 보내는 헤더] traceparent: 00-{traceId}-{A의 spanId}-01 [B가 수신 후] - A의 spanId를 자신의 parentSpanId로 사용 - 새로운 spanId를 생성해서 자신의 span 시작결과적으로 같은 정보가 전달되지만, W3C가 더 단순해진 것입니다.
현재 상황
OpenTelemetry는 CNCF에서 Kubernetes 다음으로 활발한 프로젝트가 되었습니다. AWS, Azure, GCP 같은 클라우드 벤더들도 OpenTelemetry를 지원하고, Datadog, New Relic, Dynatrace 같은 APM 벤더들도 OpenTelemetry 데이터를 수집합니다.
W3C Trace Context가 기본 전파 포맷이지만, B3와의 하위 호환성도 유지됩니다. OpenTelemetry는 Composite Propagator를 지원해서, 여러 전파 포맷을 동시에 읽고 쓸 수 있습니다.
Spring 생태계의 Tracing 변천사
Spring 생태계에서도 Tracing 지원은 여러 번의 변화를 거쳤습니다.
Spring Cloud Sleuth 시대 (Spring Boot 2.x)
오랫동안 Spring Cloud Sleuth가 Spring 애플리케이션의 Distributed Tracing을 담당했습니다. Sleuth는 내부적으로 Brave(Zipkin의 Java 클라이언트 라이브러리)를 사용했고, 별다른 설정 없이도 다음을 자동으로 처리해줬습니다:
- HTTP 요청/응답에서 B3 헤더 추출 및 주입
- 로그에 Trace ID, Span ID 자동 추가 (MDC 활용)
- RestTemplate, WebClient 등 아웃바운드 요청에 자동 전파
# Sleuth가 적용된 로그 예시
2024-01-15 10:23:45.123 INFO [order-service,abc123,def456] OrderController - Order receivedCode language: CSS (css)대괄호 안의 abc123이 Trace ID, def456이 Span ID입니다. 이 로그 포맷 덕분에 로그 검색이 한결 수월해졌습니다.
Micrometer Tracing으로의 전환 (Spring Boot 3.x)
Spring Boot 3.0에서 큰 변화가 있었습니다. Spring Cloud Sleuth는 deprecated되고, 그 기능이 Micrometer Tracing으로 이전됐습니다.
Micrometer는 원래 메트릭 수집을 위한 Facade 라이브러리였습니다. SLF4J가 로깅 API를 추상화하듯, Micrometer는 메트릭 API를 추상화합니다. Prometheus, Datadog, CloudWatch 등 어떤 백엔드를 쓰든 애플리케이션 코드는 동일합니다.
Micrometer Tracing은 같은 철학을 Tracing에 적용합니다.
Bridge가 핵심입니다. micrometer-tracing-bridge-otel을 사용하면 내부적으로 OpenTelemetry SDK가 동작하고, micrometer-tracing-bridge-brave를 사용하면 Brave가 동작합니다. 애플리케이션 코드는 Micrometer Tracing API만 사용하면 됩니다.
Bridge, Propagator, Exporter의 관계
여기서 중요한 개념 구분이 필요합니다. Bridge, Propagator, Exporter는 각각 다른 역할을 합니다.
| 개념 | 역할 | 다중 설정 |
|---|---|---|
| Bridge | Micrometer API → 구현체(OTel/Brave) 연결 | 하나만 선택 |
| Propagator | HTTP 헤더에서 Context 읽기/쓰기 (B3, W3C 등) | 여러 개 조합 가능 |
| Exporter | Trace 데이터를 백엔드로 전송 (Jaeger, OTel Collector 등) | 여러 개 설정 가능 |
Bridge는 하나만 선택합니다. OTel Bridge를 쓸지, Brave Bridge를 쓸지 결정해야 합니다.
하지만 Propagator와 Exporter는 여러 개를 동시에 사용할 수 있습니다. 이게 점진적 마이그레이션의 핵심입니다.
두 가지 방식으로 설정할 수 있습니다.
<em># 방식 1: type으로 한번에 설정 (인바운드/아웃바운드 동일하게 적용)</em>
management:
tracing:
propagation:
type:
- w3c
- b3_multiCode language: HTML, XML (xml)<em># 방식 2: consume/produce 분리 (더 세밀한 제어)</em>
management:
tracing:
propagation:
consume: <em># 인바운드: 두 포맷 모두 읽기</em>
- w3c
- b3_multi
produce: <em># 아웃바운드: W3C만 쓰기</em>
- w3cCode language: HTML, XML (xml)type은 consume과 produce에 동일한 값을 적용합니다. 점진적 마이그레이션 시 “B3로 들어오는 건 읽되, 나갈 때는 W3C만 쓴다” 같은 설정이 필요하면 consume/produce를 분리해서 사용하면 됩니다.
Exporter 다중 설정 (application.yaml):
OTel Bridge 사용 시, 해당 exporter dependency를 추가하면 application.yaml만으로 여러 백엔드에 동시 전송이 가능합니다.
<em># application.yml - OTLP와 Zipkin에 동시 전송</em>
management:
otlp:
tracing:
endpoint: http://otel-collector:4318/v1/traces
zipkin:
tracing:
endpoint: http://zipkin:9411/api/v2/spansCode language: PHP (php)필요한 dependencies:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-otel</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-otlp</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-zipkin</artifactId>
</dependency>Code language: HTML, XML (xml)💡 OTel Collector를 사용하는 대안
더 복잡한 요구사항(3개 이상 백엔드, 동적 라우팅, tail sampling 등)이 있다면 OTel Collector를 중간에 두는 방식도 있습니다:
- 애플리케이션 → Collector → 여러 백엔드
- 애플리케이션 설정 변경 없이 백엔드 추가/제거 가능
- Collector에서 샘플링, 필터링, 배치 처리 등 추가 기능 활용
이런 설정으로 다음이 가능합니다:
- 인바운드: B3 헤더로 들어오는 요청도, W3C 헤더로 들어오는 요청도 모두 처리
- 아웃바운드: 다른 서비스 호출 시 B3와 W3C 헤더를 둘 다 전송
- Export: Trace 데이터를 Jaeger와 OTel Collector에 동시 전송
💡 점진적 마이그레이션 시나리오
현재 B3를 사용 중인 MSA 환경에서 W3C로 전환한다면:
- 모든 서비스에 Propagator를
W3C, B3둘 다 지원하도록 설정- 이 상태에서 서비스들이 배포되면, 어떤 포맷이든 처리 가능
- 모든 서비스가 업데이트된 후, B3 지원을 제거
한 번에 모든 서비스를 배포할 필요 없이, 무중단으로 전환할 수 있습니다.
💡 WebFlux 사용 시 추가 설정
Spring WebFlux(Reactor 기반)를 사용한다면 Context Propagation 설정이 필요합니다:
spring: reactor: context-propagation: auto이 설정이 없으면 Reactor의 비동기 체인에서 Trace Context가 유실될 수 있습니다.
auto로 설정하면 Reactor Context와 ThreadLocal 간 자동 전파가 활성화됩니다. 자세한 원리는 다음 편에서 다룹니다.
그래서 뭘 써야 하나?
여기서 혼란이 시작됩니다. Spring Boot 3에서 Tracing을 적용하려면 다음 선택지들이 있습니다:
- Micrometer Tracing + Bridge (Spring 추천 방식)
- OpenTelemetry Java Agent (OTel 프로젝트 추천 방식)
- OpenTelemetry Spring Boot Starter (OTel 프로젝트에서 제공)
각각의 특징을 정리해봅시다.
Micrometer Tracing + Bridge
Spring Boot Actuator를 추가하면 자동 설정됩니다. Spring 생태계와의 통합이 가장 자연스럽고, Observation API를 통해 Metrics와 Tracing을 통합 관리할 수 있습니다.
dependencies 예시:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-otel</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-exporter-otlp</artifactId>
</dependency>Code language: HTML, XML (xml)OpenTelemetry Java Agent
JVM 시작 시 -javaagent 옵션으로 붙이는 방식입니다. 애플리케이션 코드를 전혀 수정하지 않아도 됩니다.
java -javaagent:opentelemetry-javaagent.jar -jar myapp.jarCode language: CSS (css)바이트코드를 런타임에 조작해서 수백 개의 라이브러리에 대한 자동 계측(auto-instrumentation)을 제공합니다. 지원 범위가 가장 넓습니다.
OpenTelemetry Spring Boot Starter
OpenTelemetry 프로젝트에서 직접 제공하는 Spring Boot 통합입니다. Micrometer를 거치지 않고 OpenTelemetry API를 직접 사용합니다.
Native Image와 Java Agent
선택 기준 중 하나로 Native Image 지원 여부가 있습니다.
GraalVM Native Image는 Java 애플리케이션을 미리 네이티브 바이너리로 컴파일(AOT, Ahead-of-Time)하는 기술입니다. 일반 JVM 방식과 비교하면:
| JVM | Native Image | |
|---|---|---|
| 시작 시간 | 수 초 | 수십 밀리초 |
| 메모리 사용량 | 높음 | 낮음 |
| 런타임 최적화 | JIT 컴파일 | 불가 |
| 바이트코드 조작 | 가능 | 불가 |
Native Image는 이미 컴파일이 완료된 상태이기 때문에, 런타임에 바이트코드를 조작하는 Java Agent 방식을 사용할 수 없습니다. Spring Boot를 Native Image로 빌드해서 빠른 시작 시간과 낮은 메모리 사용량을 얻고 싶다면, Agent 대신 라이브러리 방식(Micrometer Tracing 또는 OTel Spring Starter)을 선택해야 합니다.
💡 언제 Native Image를 고려하나?
- 서버리스 환경 (Lambda, Cloud Functions)에서 콜드 스타트 시간이 중요할 때
- 컨테이너 환경에서 메모리 비용을 줄이고 싶을 때
- CLI 도구처럼 빠른 시작이 필수인 경우
일반적인 웹 서비스라면 JVM 방식으로도 충분한 경우가 많습니다.
선택 기준
| 상황 | 추천 |
|---|---|
| Spring Boot 3 + JVM만 사용 | Micrometer Tracing + OTel Bridge |
| GraalVM Native Image 필요 | Micrometer Tracing (Agent 불가) |
| 다중 언어 MSA (Java + Go + Python) | API 사용 일관성을 위해 OpenTelemetry SDK 직접 사용 또는 Java Agent |
| 기존 Zipkin 인프라 유지 | Micrometer Tracing + Brave Bridge |
| 가장 넓은 자동 계측 원함 | OpenTelemetry Java Agent |
| 코드 변경 최소화 | OpenTelemetry Java Agent |
정리하면:
- Spring 생태계에 깊이 통합하고, Metrics/Tracing을 통합 관리하고 싶다면 Micrometer Tracing
- 코드 변경 없이 가장 광범위한 자동 계측을 원한다면 OpenTelemetry Java Agent
- 다중 언어 환경에서 일관된 API를 사용하고 싶다면 OpenTelemetry SDK 직접 사용
💡 opentelemetry-spring-boot-starter와 micrometer-tracing-bridge-otel 비교
- 둘 다 라이브러리 방식
opentelemetry-spring-boot-starter: OpenTelemetry 프로젝트에서 제공. OTel API를 직접 사용micrometer-tracing-bridge-otel: Micrometer API를 사용하고, 내부적으로 OTel SDK로 변환둘 다 결국 OpenTelemetry 프로토콜(OTLP)로 데이터를 내보냅니다. 차이는 애플리케이션 코드에서 어떤 API를 사용하느냐입니다. 다만 OpenTelemetry 문서에서 언급한 기본 방식은 Java Agent입니다. 그리고 현재 지원하는 instrumentation 종류가 Micrometer 구현체 쪽이 더 많습니다(ex: reactive mongo client, redis client 등). 그래서 Spring 애플리케이션에서 Tracing을 라이브러리 방식으로 한다면 Micrometer 구현체가 좀더 적합하다고 생각합니다.
다음 편 예고
이번 글에서는 Distributed Tracing의 개념과 역사, 그리고 Spring 생태계에서의 선택지를 살펴봤습니다. 하지만 “어떻게 동작하는가”에 대해서는 아직 다루지 않았습니다.
다음 글에서는 Tracing Context가 어떻게 전파되는지 깊이 파고듭니다.
- ThreadLocal이 뭐고, 왜 Tracing에서 핵심인지
- MDC(Mapped Diagnostic Context)가 정확히 어떻게 동작하는지
- SLF4J, Logback이 각각 어떤 역할을 하는지
동기 방식(Thread per Request)에서의 Context 전파 원리를 이해하면, 이후 비동기 환경(Reactor, Coroutine)에서의 복잡성도 자연스럽게 이해할 수 있습니다.