서론
Kubernetes를 사용하다 보면 “내 요청이 정확히 어떤 경로로 Pod까지 도달하는 걸까?”라는 의문이 생깁니다. kubectl apply로 Ingress와 Service를 배포하면 마법처럼 트래픽이 흘러가지만, 문제가 생겼을 때 어디를 봐야 할지 막막해지는 경험을 해보셨을 겁니다.
이 글에서는 외부 사용자의 HTTP 요청이 Kubernetes 클러스터 내부의 Pod까지 도달하는 전체 과정을 단계별로 분석합니다. 각 구간에서 어떤 컴포넌트가 어떤 역할을 하는지, 그리고 그 과정에서 흔히 혼동되는 개념들(Ingress vs Service, kube-proxy의 정체 등)을 명확히 정리해 드리겠습니다.
전체 트래픽 흐름 한눈에 보기
외부 요청이 Pod에 도달하는 전체 흐름은 다음과 같습니다.
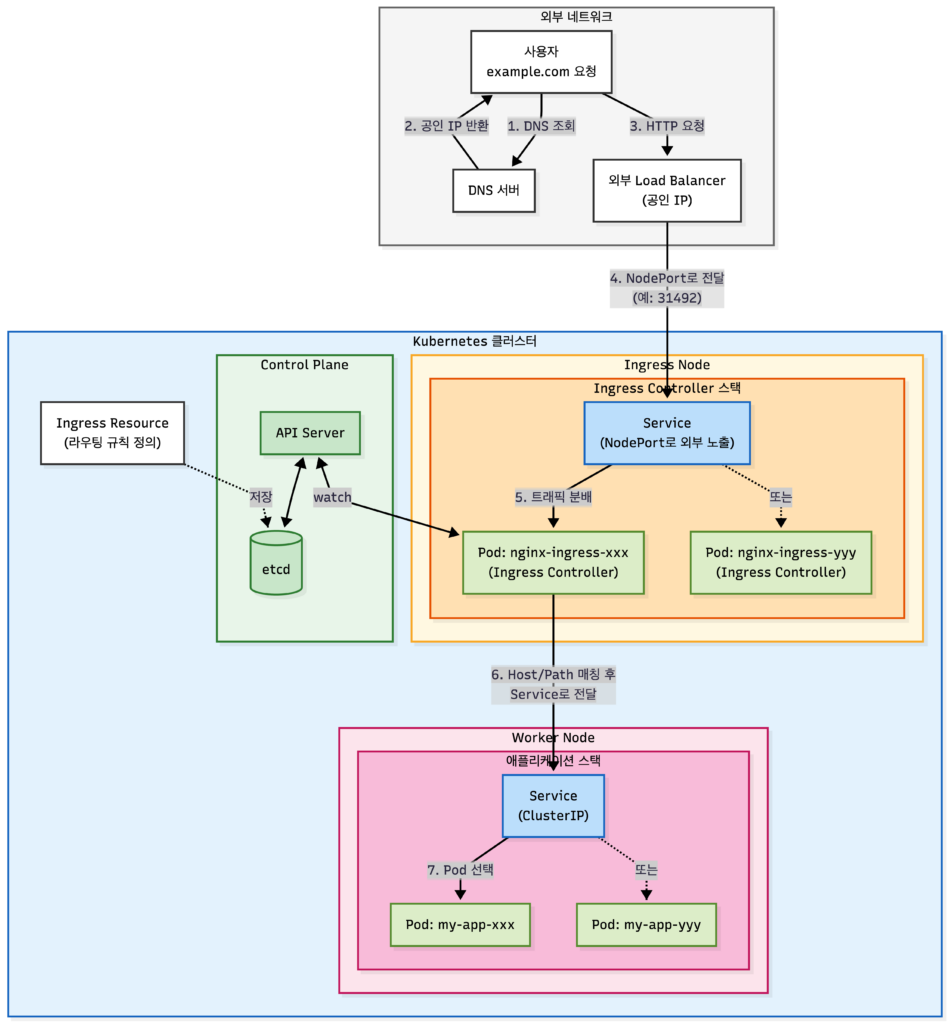
사용자 → DNS → 외부 LB → Ingress Node Service → Ingress Controller Pod → Worker Node Service → Worker Node Pod각 단계를 간략히 살펴보면:
| 단계 | 구간 | 핵심 역할 |
|---|---|---|
| ① | 사용자 → DNS | 도메인을 공인 IP로 변환 |
| ② | DNS → 외부 LB | 공인 IP로 트래픽 전달 |
| ③ | 외부 LB → Ingress Node | NodePort를 통해 클러스터 내부로 트래픽 진입 |
| ④ | Ingress Node → Ingress Controller | Service를 통해 Ingress Controller Pod으로 전달 |
| ⑤ | Ingress Controller → Service | Host/Path 기반으로 목적지 Service 결정 |
| ⑥ | Service → Pod | 최종 목적지 Pod로 트래픽 전달 |
이제 각 구간을 상세히 들여다보겠습니다.
미리 알아두면 좋은 것
“Ingress Node”나 “Ingress Controller”라는 이름 때문에 특별한 K8s 오브젝트처럼 느껴질 수 있지만, 실제로는 모두 일반적인 Service + Pod 구조입니다. Ingress Node는 라벨이 붙은 일반 Worker Node이고, Ingress Controller도 DaemonSet이나 Deployment로 배포된 일반 Pod입니다. 이 점을 기억하면서 읽으시면 전체 흐름이 훨씬 명확해집니다.
외부 LB에서 Ingress Node까지
노드 라벨링으로 역할 분리하기
Kubernetes에는 공식적으로 “Ingress Node”라는 노드 타입이 존재하지 않습니다. 모든 노드는 기본적으로 동일한 Worker Node이며, 라벨(Label)을 통해 역할을 구분합니다.
# 특정 노드에 ingress 역할 라벨 부여
kubectl label node node-1 node-role=ingress
kubectl label node node-2 node-role=ingressCode language: PHP (php)그리고 Ingress Controller를 배포할 때 nodeSelector나 nodeAffinity를 설정하여 해당 라벨이 있는 노드에만 Pod가 배포되도록 합니다.
# Ingress Controller DaemonSet 예시 (일부)
spec:
template:
spec:
nodeSelector:
node-role: ingressCode language: PHP (php)“Ingress Node”는 공식 용어가 아닙니다
K8s 공식 문서에서 “Ingress Node”라는 용어는 사용하지 않습니다. 이는 운영 편의상 Ingress Controller가 배포된 노드를 지칭하는 관례적 표현입니다. 실제로는 라벨과 스케줄링 설정으로 논리적 역할을 부여한 일반 Worker Node입니다.
Load Balancer가 대상 노드를 아는 방법
외부 Load Balancer는 어떻게 트래픽을 보낼 노드를 알 수 있을까요?
핵심부터 말하면, 외부 LB는 NodePort를 통해 클러스터로 트래픽을 전달합니다. 환경에 따라 다른 것은 이 연결이 자동으로 설정되느냐, 수동으로 설정해야 하느냐입니다.
클라우드 환경 (AWS, GCP, Azure 등)
LoadBalancer 타입의 Service를 생성하면 클라우드 프로바이더가 자동으로 처리합니다.
apiVersion: v1
kind: Service
metadata:
name: ingress-nginx-controller
spec:
type: LoadBalancer # 클라우드에서 외부 LB 자동 생성
selector:
app: ingress-nginx
ports:
- port: 80
targetPort: 80Code language: PHP (php)이 Service를 생성하면:
- NodePort가 자동 할당됨 (예: 31492)
- 클라우드 LB가 자동 생성됨
- LB가 NodePort로 트래픽을 보내도록 자동 설정됨
# 생성 후 확인
kubectl get svc ingress-nginx-controller -n ingress-nginx
# 출력 예시: 80:31492는 "Service포트:NodePort"를 의미
NAME TYPE EXTERNAL-IP PORT(S)
ingress-nginx-controller LoadBalancer 52.12.34.56 80:31492/TCP,443:31917/TCPCode language: PHP (php)온프레미스 환경
클라우드와 달리 외부 LB를 자동으로 생성해줄 주체가 없습니다. 두 가지 방법이 있습니다:
방법 1: NodePort 타입 + 외부 LB 수동 설정
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30080외부 LB(F5, HAProxy 등)에 직접 노드 IP와 NodePort를 등록합니다. 가장 단순한 방법입니다.
방법 2: LoadBalancer 타입 + MetalLB
MetalLB는 온프레미스에서도 클라우드처럼 EXTERNAL-IP를 자동 할당해주는 솔루션입니다. MetalLB를 설치하면 LoadBalancer 타입 Service 생성 시 자동으로 IP가 할당됩니다.
EXTERNAL-IP란?
kubectl get svc출력에서 보이는 EXTERNAL-IP는 노드 IP가 아닙니다. LoadBalancer Service에 할당되는 외부 접근용 IP입니다.# 클라우드: Cloud Controller가 LB를 만들고 IP 할당 NAME TYPE EXTERNAL-IP PORT(S) my-service LoadBalancer 52.12.34.56 80:31492/TCP # 온프레미스 (MetalLB 없음): 할당 주체가 없어서 대기 상태 NAME TYPE EXTERNAL-IP PORT(S) my-service LoadBalancer <pending> 80:31492/TCPCode language: PHP (php)온프레미스에서 MetalLB 없이 LoadBalancer 타입을 쓰면 EXTERNAL-IP가 계속
<pending>상태로 남습니다. 이 경우 결국 NodePort로 직접 연결해야 하므로 방법 1과 동일해집니다.
Service 타입의 계층 구조
K8s Service 타입은 상위 타입이 하위 타입을 포함하는 계층 구조입니다.
Service 타입 포함하는 것 추가되는 것 ClusterIP – 클러스터 내부 IP 할당 NodePort ClusterIP + 모든 노드에 포트 오픈 (30000-32767) LoadBalancer NodePort + 외부 LB 프로비저닝 요청 즉, LoadBalancer 타입 = NodePort + 외부 LB 자동 생성 요청입니다. 그래서 LoadBalancer 타입으로 만들어도 NodePort가 자동 할당되고, 결국 트래픽은 NodePort를 통해 들어옵니다.
LoadBalancer 타입 설정시 환경에 따른 차이
환경 LoadBalancer 타입 Service 생성 시 클라우드 (AWS, GCP 등) 외부 LB 자동 생성 + NodePort 연결 자동 설정 온프레미스 EXTERNAL-IP가 <pending>상태, 별도 외부 LB에 NodePort 수동 연결 필요클라우드든 온프레미스든 최종적으로 외부 LB는 NodePort를 통해 클러스터와 통신합니다.
궁금증: NodePort를 쓰면 모든 노드로 트래픽이 가는 건가요?
NodePort는 모든 노드에서 해당 포트를 열어줍니다. 하지만 트래픽이 도착한 노드에 해당 Pod가 없으면, 내부적으로 Pod가 있는 노드로 다시 라우팅됩니다. 이 과정에서 추가 네트워크 홉이 발생할 수 있어, 성능을 위해
externalTrafficPolicy: Local옵션을 고려하기도 합니다.
Ingress Node에서 Ingress Controller Pod까지
Ingress Controller의 배포 구조
Ingress Controller는 보통 DaemonSet 또는 Deployment로 배포됩니다.
| 배포 방식 | 특징 | 사용 케이스 |
|---|---|---|
| DaemonSet | 지정된 모든 노드에 1개씩 Pod 배포 | 고가용성, 트래픽 분산 |
| Deployment | 지정된 replica 수만큼 Pod 배포 | 유연한 스케일링 |
DaemonSet을 사용하면 Ingress 역할 노드마다 하나의 nginx Pod가 실행되어, Load Balancer가 어떤 노드로 트래픽을 보내도 처리할 수 있습니다.
Ingress Controller란 정확히 무엇인가?
“Controller”라는 이름은 Kubernetes의 Controller 패턴에서 유래했습니다. Controller는 “원하는 상태(Desired State)”와 “실제 상태(Actual State)”를 일치시키는 역할을 합니다.
Ingress Controller의 경우:
- 원하는 상태: 클러스터에 정의된 Ingress 리소스들의 라우팅 규칙
- 실제 상태: nginx.conf 파일의 설정
- Controller의 역할: API Server를 watch하면서 Ingress 변경을 감지하고, nginx 설정을 업데이트
결국 Ingress Controller는 “특별한 권한(ClusterRole)을 가지고 전체 클러스터의 Ingress 리소스를 watch하면서 자신의 nginx 설정을 동적으로 업데이트하는 nginx Pod”입니다.
핵심: Ingress Controller도 결국 Service + Pod 구조입니다
많은 분들이 Ingress Controller를 특별한 K8s 오브젝트로 오해하지만, 실제 구조는 일반 애플리케이션과 동일합니다:
구성 요소 Ingress Controller 일반 애플리케이션 Pod nginx-ingress-xxx my-app-xxx Service NodePort로 외부 노출 ClusterIP (내부 전용) 배포 방식 DaemonSet 또는 Deployment Deployment 차이점은 Ingress Controller의 Service가 NodePort를 통해 외부 트래픽을 받는다는 것뿐입니다. 트래픽 흐름도 동일합니다: 외부 LB → NodePort → Service → Pod
Ingress Controller의 라우팅 결정
API Server Watch 메커니즘
Ingress Controller는 어떻게 클러스터 전체의 Ingress 리소스를 알 수 있을까요? 답은 Kubernetes API Server의 watch 기능입니다.
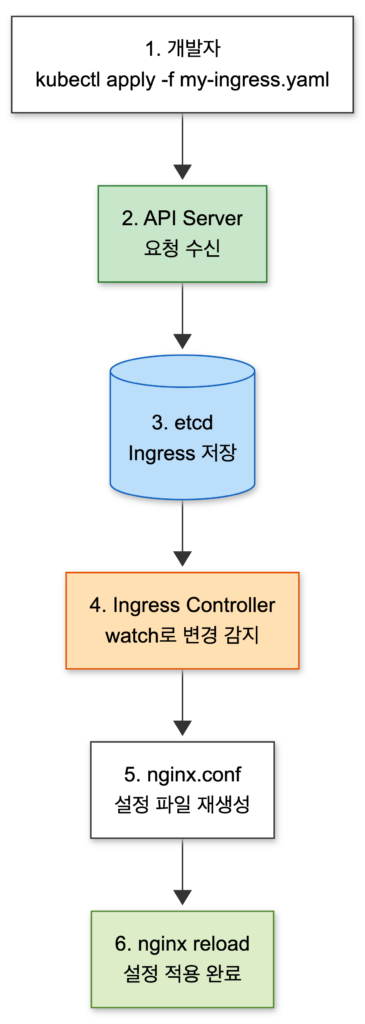
동기화 흐름을 단계별로 정리하면 다음과 같습니다:
- 개발자가
kubectl apply -f my-ingress.yaml로 Ingress 리소스 생성 - API Server가 요청을 받아 etcd에 저장
- Ingress Controller가 watch를 통해 변경 감지
- Ingress 규칙을 nginx.conf로 변환
- nginx reload로 설정 적용
Ingress Controller는 시작할 때 API Server에 watch 요청을 보냅니다. 이후 클러스터 어디서든 Ingress 리소스가 생성/수정/삭제되면 실시간으로 알림을 받습니다.
Ingress 리소스가 nginx.conf로 변환되는 과정
다음과 같은 Ingress 리소스가 있다고 가정해 봅시다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-app-ingress
namespace: production
spec:
rules:
- host: api.example.com
http:
paths:
- path: /users
pathType: Prefix
backend:
service:
name: user-service
port:
number: 80
- path: /orders
pathType: Prefix
backend:
service:
name: order-service
port:
number: 80Ingress Controller는 이 리소스를 읽어서 대략 다음과 같은 nginx 설정으로 변환합니다.
# 자동 생성된 nginx.conf (단순화된 예시)
server {
listen 80;
server_name api.example.com;
location /users {
proxy_pass http://production-user-service-80;
}
location /orders {
proxy_pass http://production-order-service-80;
}
}Code language: PHP (php)이렇게 변환된 설정은 nginx에 reload되어 즉시 적용됩니다.
Ingress vs Service, 뭐가 다른가?
구분 Ingress Service OSI 계층 L7 (HTTP/HTTPS) L4 (TCP/UDP) 주요 기능 Host/Path 기반 라우팅 Pod 그룹에 대한 로드밸런싱 실제 동작 Ingress Controller가 규칙을 읽어서 처리 kube-proxy가 iptables/IPVS로 구현 비유 교통 표지판 (어디로 갈지 안내) 도로 (실제 이동 경로) 핵심은 Ingress는 “라우팅 규칙”의 정의이고, **Service는 “실제 트래픽 전달”**을 담당한다는 점입니다. Ingress Controller가 요청을 받아 어떤 Service로 보낼지 결정하면, 그 이후는 Service가 담당합니다.
Service에서 Pod까지: kube-proxy와 iptables
이제 Ingress Controller가 목적지 Service를 결정했습니다. 그런데 Service의 ClusterIP는 가상 IP입니다. 실제로 트래픽을 받을 수 있는 네트워크 인터페이스가 없습니다. 그렇다면 이 가상 IP로 보낸 트래픽은 어떻게 실제 Pod에 도달할까요?
kube-proxy의 역할
이 마법을 담당하는 것이 바로 kube-proxy입니다.
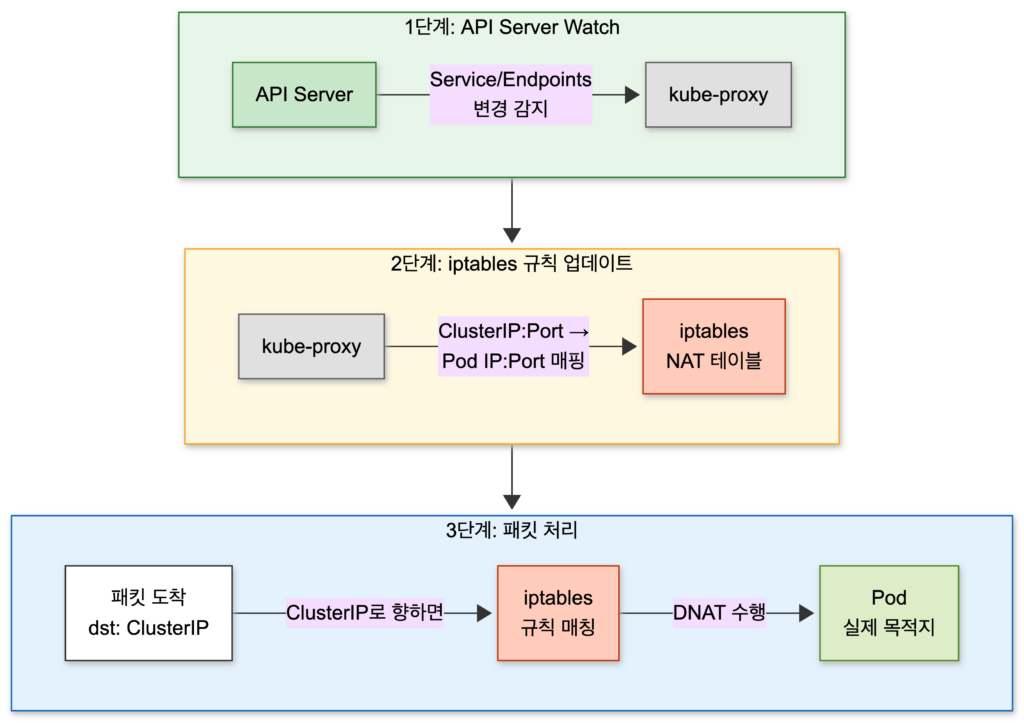
kube-proxy의 동작을 3단계로 나눠보면:
- API Server Watch: Service와 Endpoints 리소스 변경을 실시간 감지
- iptables 규칙 업데이트: ClusterIP:Port → Pod IP:Port 매핑 규칙 생성
- 패킷 처리: ClusterIP로 향하는 패킷을 가로채서 실제 Pod IP로 DNAT 수행
kube-proxy는 어디에 있는가?
kube-proxy는 DaemonSet으로 배포되어 모든 노드에서 실행됩니다.
$ kubectl get daemonset -n kube-system NAME DESIRED CURRENT READY NODE SELECTOR kube-proxy 5 5 5 <none> $ kubectl get pods -n kube-system -l k8s-app=kube-proxy NAME READY STATUS RESTARTS AGE kube-proxy-abc12 1/1 Running 0 10d kube-proxy-def34 1/1 Running 0 10d ...Code language: JavaScript (javascript)참고로 Cilium 같은 eBPF 기반 CNI를 사용하는 환경에서는 kube-proxy 없이 동작하기도 합니다. Cilium은 eBPF 프로그램으로 커널 레벨에서 직접 패킷을 처리하여 더 나은 성능을 제공합니다.
iptables 규칙 살펴보기
kube-proxy가 만드는 iptables 규칙을 직접 확인해 봅시다.
# Service 관련 iptables 규칙 확인
sudo iptables -t nat -L KUBE-SERVICES -n | head -20Code language: PHP (php)예를 들어 user-service라는 ClusterIP Service가 있다면, 다음과 같은 규칙 체인이 생성됩니다.
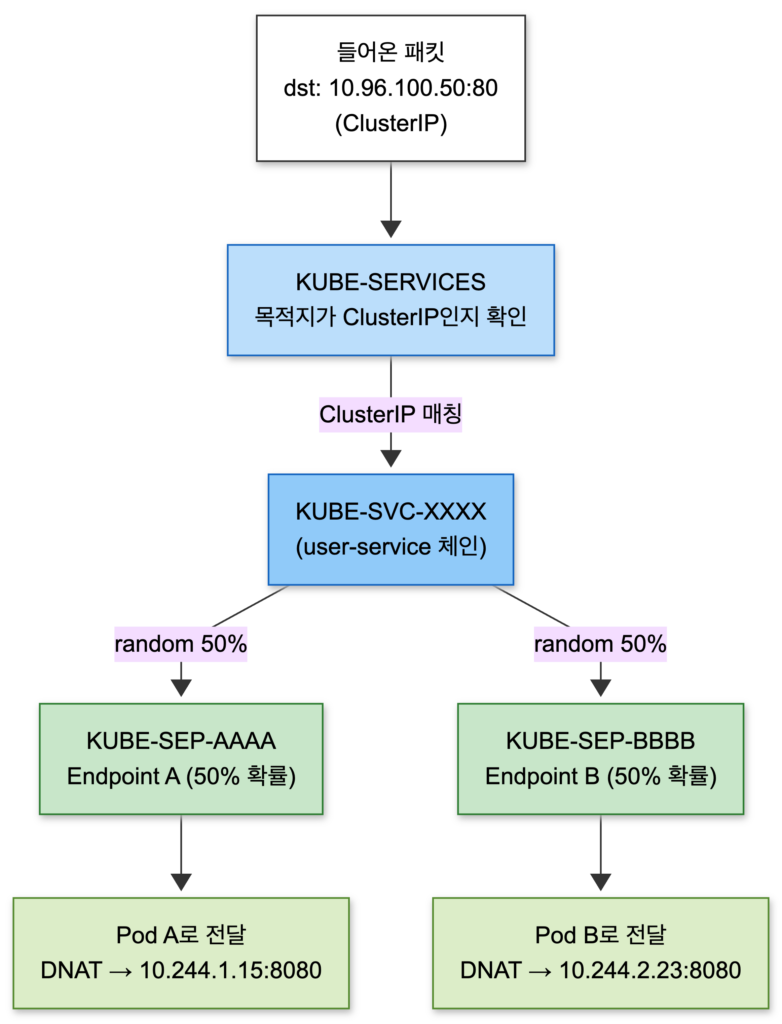
| 체인 이름 | 역할 | 설명 |
|---|---|---|
| KUBE-SERVICES | 진입점 | 목적지가 ClusterIP인지 확인 |
| KUBE-SVC-XXXX | Service 체인 | 해당 Service의 Endpoint들로 분기 |
| KUBE-SEP-AAAA | Endpoint 체인 | Pod A로 DNAT (10.244.1.15:8080) |
| KUBE-SEP-BBBB | Endpoint 체인 | Pod B로 DNAT (10.244.2.23:8080) |
체인 이름의 의미
- KUBE-SVC: Service의 약자로, Service 전체를 대표하는 체인
- KUBE-SEP: Service EndPoint의 약자로, 개별 Pod(Endpoint)를 위한 체인
DNAT(Destination NAT)이 핵심입니다. 패킷의 목적지 IP를 ClusterIP에서 실제 Pod IP로 변경합니다. 여러 Pod가 있을 때는 statistic mode random 모듈로 확률 기반 로드밸런싱을 수행합니다.
실제 iptables 규칙은 다음과 같은 형태입니다.
# 실제 iptables 규칙 예시 (단순화)
-A KUBE-SVC-XXXX -m statistic --mode random --probability 0.5 -j KUBE-SEP-AAAA
-A KUBE-SVC-XXXX -j KUBE-SEP-BBBB
-A KUBE-SEP-AAAA -p tcp -j DNAT --to-destination 10.244.1.15:8080
-A KUBE-SEP-BBBB -p tcp -j DNAT --to-destination 10.244.2.23:8080Code language: CSS (css)궁금증: iptables 규칙이 너무 많아지면 성능 문제가 없나요?
맞습니다. iptables는 규칙을 순차적으로 평가하므로 Service와 Pod 수가 많아지면 성능 저하가 발생할 수 있습니다. 이를 해결하기 위한 대안으로:
- IPVS((IP Virtual Server) 모드: kube-proxy의 또 다른 모드로, 해시 테이블 기반이라 규칙 수에 관계없이 O(1) 성능
- eBPF 기반 (Cilium 등): 커널 레벨에서 직접 패킷 처리, iptables 완전 대체 가능
응답의 역방향 흐름
요청이 Pod에 도달했으니, 이제 응답이 돌아가는 과정을 살펴봅시다. 다행히 역방향은 비교적 단순합니다.
conntrack과 상태 유지
Linux 커널의 conntrack(Connection Tracking) 모듈이 핵심 역할을 합니다. 요청 패킷이 들어올 때 DNAT 변환 정보를 conntrack 테이블에 기록해 둡니다.
| 구분 | 출발지 (src) | 목적지 (dst) |
|---|---|---|
| Original (요청) | 192.168.1.100 | 10.96.100.50:80 (ClusterIP) |
| Reply (응답) | 10.244.1.15:8080 (Pod IP) | 192.168.1.100 |
| DNAT 변환 | – | 10.96.100.50:80 → 10.244.1.15:8080 |
응답 패킷이 Pod에서 나올 때, conntrack은 이 정보를 보고 자동으로 역방향 NAT인 SNAT(Source NAT)를 수행합니다. DNAT이 목적지 IP를 변경했다면, SNAT은 출발지 IP를 변경합니다. 응답 패킷의 소스 IP가 Pod IP(10.244.1.15)에서 ClusterIP(10.96.100.50)로 변환되어 원래 요청자에게 돌아갑니다.
응답 흐름: Pod → (conntrack SNAT) → Service → Ingress Controller → LB → 사용자궁금증: 응답도 같은 경로로 돌아가나요?
네트워크 구성에 따라 다를 수 있습니다. 일반적으로 conntrack 기반 NAT가 제대로 동작하면 같은 경로로 돌아갑니다. 하지만 비대칭 라우팅(Asymmetric Routing) 상황에서는 응답이 다른 경로로 나가면서 conntrack 상태를 찾지 못해 패킷이 드롭될 수 있습니다. 이는 멀티 네트워크 환경이나 복잡한 LB 구성에서 주의해야 할 점입니다.
심화: 현대적 대안들
지금까지 설명한 kube-proxy + iptables 방식은 Kubernetes의 전통적인 네트워킹 구현입니다. 하지만 최근에는 더 효율적인 대안들이 등장했습니다.
Cilium과 eBPF
eBPF(extended Berkeley Packet Filter)는 Linux 커널 내부에서 샌드박스화된 프로그램을 실행할 수 있게 해주는 기술입니다. Cilium은 이를 활용하여 kube-proxy를 완전히 대체합니다.
| 비교 항목 | kube-proxy (iptables) | Cilium (eBPF) |
|---|---|---|
| 처리 위치 | User space → Kernel | Kernel 내부 직접 처리 |
| 규칙 탐색 | O(n) 순차 탐색 | O(1) 해시 탐색 |
| 규칙 업데이트 | 전체 테이블 재작성 | 개별 항목 업데이트 |
| 부가 기능 | 없음 | NetworkPolicy, 관측성 등 |
NetworkPolicy
Kubernetes의 NetworkPolicy는 Pod 간 트래픽을 제어하는 방화벽 규칙입니다. CNI 플러그인(Calico, Cilium 등)이 이를 구현합니다.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-frontend-only
spec:
podSelector:
matchLabels:
app: backend
ingress:
- from:
- podSelector:
matchLabels:
app: frontendCode language: JavaScript (javascript)etcd: 모든 정보의 저장소
앞서 언급한 모든 리소스(Ingress, Service, Endpoints, Pod 등)는 etcd에 저장됩니다. etcd는 Kubernetes의 유일한 영구 저장소로, Control Plane 노드(예전 용어로 Master 노드)에서 실행됩니다.
# etcd 내부 저장 경로 예시
/registry/services/specs/default/user-service
/registry/services/endpoints/default/user-service
/registry/ingress/production/my-app-ingress
/registry/pods/production/user-app-abc123Code language: PHP (php)API Server만이 etcd와 직접 통신하며, 다른 모든 컴포넌트(kube-proxy, Ingress Controller 등)는 API Server를 통해 데이터에 접근합니다.
실전 트러블슈팅 팁
트래픽이 Pod에 도달하지 않을 때, 어디서 막혔는지 구간별로 확인하는 방법입니다.
구간별 확인 명령어
1. DNS 확인
nslookup api.example.com
dig api.example.comCode language: CSS (css)2. LB → Ingress Node 확인
# Ingress Controller Pod 상태
kubectl get pods -n ingress-nginx
# Ingress Controller Service 확인
kubectl get svc -n ingress-nginxCode language: PHP (php)3. Ingress Controller 로그
kubectl logs -n ingress-nginx -l app.kubernetes.io/name=ingress-nginx4. Ingress 리소스 확인
kubectl get ingress -A
kubectl describe ingress my-ingress -n productionCode language: JavaScript (javascript)5. Service → Pod 확인
# Service와 Endpoints 확인
kubectl get svc,endpoints -n production
# Endpoints가 비어있으면 Pod selector 문제
kubectl describe svc user-service -n productionCode language: PHP (php)6. Pod 상태 및 로그
kubectl get pods -n production
kubectl logs user-app-abc123 -n productionCode language: JavaScript (javascript)자주 발생하는 문제와 해결
| 증상 | 가능한 원인 | 확인 방법 |
|---|---|---|
| 503 Service Unavailable | Endpoints가 없음 | kubectl get endpoints |
| 404 Not Found | Ingress path 불일치 | Ingress spec 확인 |
| Connection refused | Pod가 Ready가 아님 | kubectl get pods |
| Timeout | NetworkPolicy 차단 | NetworkPolicy 확인 |
마치며
외부 요청이 Kubernetes Pod에 도달하는 여정을 정리하면 다음과 같습니다.
- DNS 조회로 도메인이 공인 IP로 변환
- 외부 Load Balancer가 트래픽을 클러스터로 전달
- Ingress Controller가 Host/Path 기반으로 목적지 Service 결정
- kube-proxy가 관리하는 iptables가 ClusterIP를 실제 Pod IP로 변환
- Pod가 요청을 처리하고 응답
이 흐름을 이해하면 “왜 트래픽이 안 들어오지?”라는 문제를 체계적으로 디버깅할 수 있습니다. 각 구간의 역할과 확인 포인트를 기억해 두면 트러블슈팅 시간을 크게 줄일 수 있을 것입니다.