들어가며
이전 글에서는 Kubernetes 클러스터 내부에서 Pod끼리 어떻게 통신하는지 살펴봤습니다. CNI 플러그인이 네트워크를 구성하고, CoreDNS가 서비스 디스커버리를 담당한다는 것을 알게 됐죠.
그런데 그 Pod는 애초에 어떻게 생성되고 실행되는 걸까요?
kubectl apply -f deployment.yaml을 실행하면 마법처럼 Pod가 생성됩니다. 하지만 그 사이에는 여러 구성요소가 협력하는 복잡한 과정이 있습니다.
이 글에서는 다음 질문들에 답합니다:
- 컨트롤 플레인(마스터 노드)과 워커 노드는 각각 뭘 하는 걸까?
kubectl apply하면 내부에서 어떤 일이 일어날까?- 스케줄러는 어떤 기준으로 노드를 선택할까?
- Pod의 리소스(CPU, Memory)는 어떻게 관리될까?
- Pod가 정상인지 어떻게 확인할까?
전체 그림: 컨트롤 플레인과 워커 노드
Kubernetes 클러스터는 크게 컨트롤 플레인(Control Plane)과 워커 노드(Worker Node)로 나뉩니다.
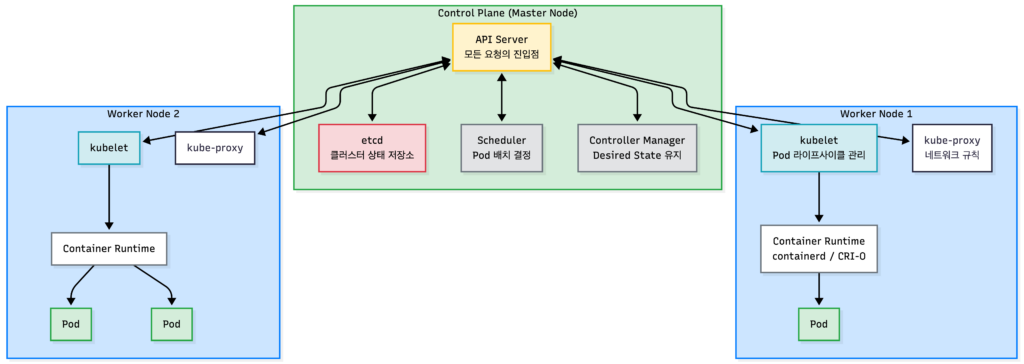
왜 이렇게 나눠져 있을까?
컨트롤 플레인은 클러스터의 “두뇌”입니다. 무엇을 어디에 배치할지 결정하고, 원하는 상태를 유지합니다.
워커 노드는 “손발”입니다. 실제로 컨테이너를 실행하고 트래픽을 처리합니다.
이렇게 분리하면 컨트롤 플레인이 일시적으로 죽어도 기존 Pod들은 계속 실행됩니다. 새로운 Pod를 생성하거나 스케일링은 못 하지만, 이미 실행 중인 워크로드는 영향받지 않습니다.
컨트롤 플레인 구성요소
| 구성요소 | 역할 | 비유 |
|---|---|---|
| API Server | 모든 요청의 진입점. 인증, 인가, 요청 검증 | 안내 데스크 |
| etcd | 클러스터의 모든 상태를 저장하는 분산 저장소 | 데이터베이스 |
| Scheduler | Pod를 어느 노드에 배치할지 결정 | 배치 담당자 |
| Controller Manager | 원하는 상태를 유지 (ReplicaSet, Deployment 등) | 관리 감독관 |
워커 노드 구성요소
| 구성요소 | 역할 | 비유 |
|---|---|---|
| kubelet | 노드의 에이전트. Pod 라이프사이클 관리 | 현장 감독 |
| 컨테이너 런타임 | 실제 컨테이너 실행 (containerd, CRI-O) | 작업자 |
| kube-proxy | Service → Pod 라우팅 규칙 관리 | 이정표 관리자 |
네트워크 편에서 다룬 구성요소들
kube-proxy는 네트워크 이해하기 (1)에서 다뤘습니다. CNI 플러그인도 워커 노드에서 동작하며, 네트워크 이해하기 (2)에서 상세히 설명했습니다.
Pod 생성 흐름: kubectl apply부터 컨테이너 실행까지
이제 kubectl apply -f deployment.yaml을 실행했을 때 내부에서 어떤 일이 일어나는지 추적해보겠습니다.
Deployment 매니페스트 구조
먼저 Deployment yaml 파일의 기본 구조를 살펴보겠습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3 # Pod 개수
selector:
matchLabels:
app: my-app
template: # Pod 템플릿
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-app:1.0
ports:
- containerPort: 8080
resources: # 리소스 설정
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"Code language: PHP (php)| 필드 | 설명 |
|---|---|
replicas | 유지할 Pod 개수 |
selector | 이 Deployment가 관리할 Pod를 찾는 기준 |
template | 생성할 Pod의 템플릿 (라벨, 컨테이너 정의) |
resources | CPU/Memory 요청량과 제한 |
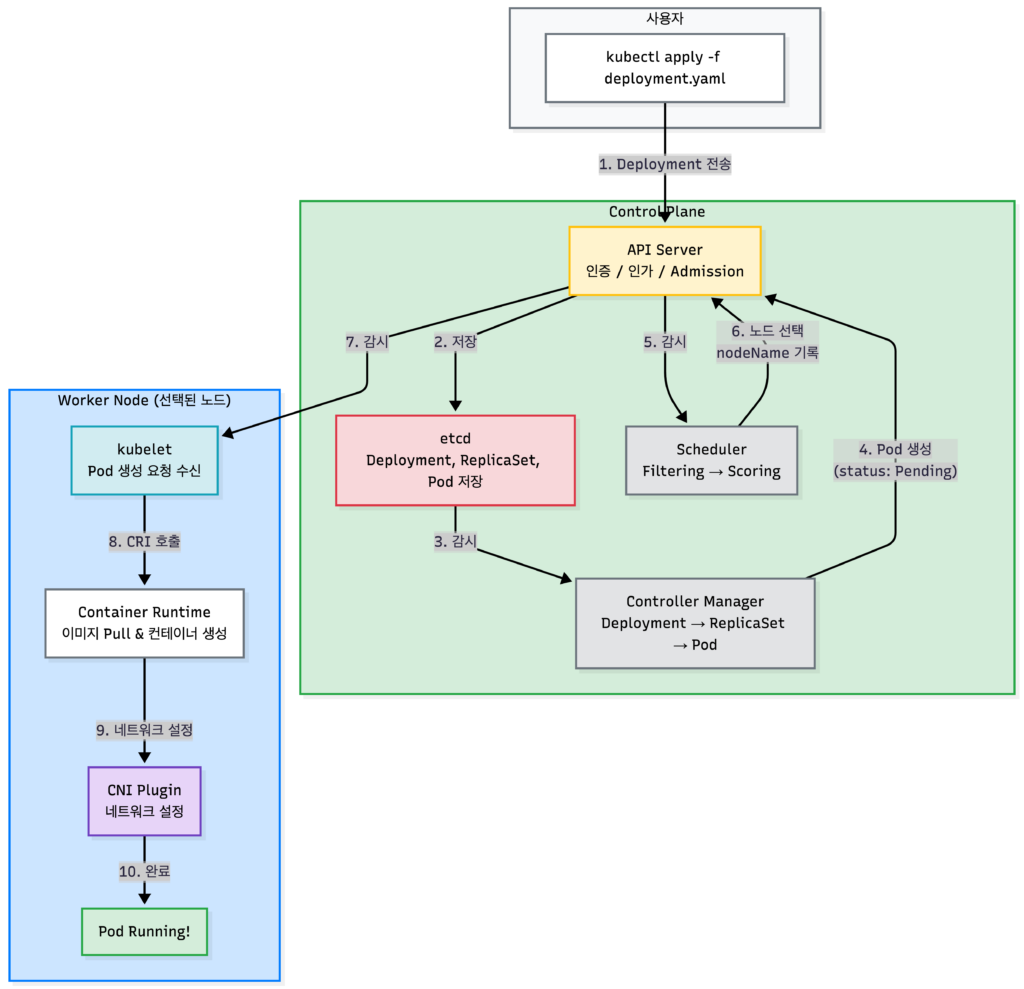
1단계: kubectl → API Server
kubectl apply -f deployment.yamlCode language: CSS (css)kubectl은 Deployment 정의를 API Server에 전송합니다. API Server는 다음을 수행합니다:
- 인증(Authentication): 요청자가 누구인지 확인
- 인가(Authorization): 이 작업을 할 권한이 있는지 확인
- Admission Control: 요청을 검증하고 필요시 수정 (예: 기본값 주입)
2단계: Controller Manager가 Pod 생성
Deployment를 생성하면 Controller Manager가 개입합니다:
- Deployment Controller가 ReplicaSet 생성
- ReplicaSet Controller가
replicas수만큼 Pod 생성 - 생성된 Pod는 etcd에 저장되고, 상태는 Pending
status:
phase: Pending
# nodeName은 아직 비어 있음Code language: PHP (php)Controller Manager의 역할
Controller Manager는 “replicas: 3이면 Pod가 3개 있어야 해”라는 원하는 상태(Desired State)를 유지합니다. Pod가 죽으면 새로 생성하고, replicas를 줄이면 Pod를 삭제합니다.
Deployment 외에 다른 워크로드 리소스들
Deployment → ReplicaSet → Pod 구조는 stateless 앱에 적합합니다. 하지만 다른 패턴이 필요한 경우도 있습니다.
리소스 용도 Pod 특징 Deployment 일반 stateless 앱 (웹 서버, API) 이름 랜덤, 어느 노드든 OK DaemonSet 모든 노드에 실행 (로그 수집기, 모니터링 에이전트) 노드당 1개씩 자동 배치 StatefulSet 상태 있는 앱 (DB, Kafka, Redis 클러스터) 고정 이름, 순서대로 생성/삭제 DaemonSet과 StatefulSet은 Deployment를 거치지 않고 직접 Pod를 생성합니다.
# DaemonSet 예시: 모든 노드에 로그 수집기 배포 apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: containers: - name: fluentd image: fluentd:latestCode language: PHP (php)# StatefulSet 예시: Redis 클러스터 apiVersion: apps/v1 kind: StatefulSet metadata: name: redis spec: serviceName: redis # Headless Service 필요 replicas: 3 selector: matchLabels: app: redis template: metadata: labels: app: redis spec: containers: - name: redis image: redis:7 volumeClaimTemplates: # Pod마다 별도 볼륨 생성 - metadata: name: data spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 1GiCode language: PHP (php)StatefulSet의 Pod는
redis-0,redis-1,redis-2처럼 순번이 붙은 고정 이름을 가지며, 0번부터 순서대로 생성되고 역순으로 삭제됩니다.
3단계: Scheduler가 노드 선택
Scheduler는 API Server를 지속적으로 감시(watch)합니다. nodeName이 비어 있는 새 Pod가 생기면:
- Filtering: 조건에 맞지 않는 노드 제외
- Scoring: 남은 노드에 점수를 매겨 최적의 노드 선택
- 선택한 노드를 Pod의
spec.nodeName에 기록
spec:
nodeName: worker-2 # Scheduler가 결정Code language: PHP (php)4단계: kubelet이 Pod 생성 요청 수신
worker-2의 kubelet은 API Server를 감시하다가 자신에게 배정된 Pod를 발견합니다. kubelet은 CRI(Container Runtime Interface)를 통해 컨테이너 런타임에 Pod 생성을 요청합니다.
5단계: 컨테이너 런타임이 컨테이너 실행
컨테이너 런타임(containerd, CRI-O 등)은:
- 컨테이너 이미지를 Pull
- 컨테이너를 생성하고 시작
- CNI 플러그인을 호출해 네트워크 설정 (이 부분은 네트워크 이해하기 (2)에서 다뤘습니다)
6단계: Pod Running!
모든 컨테이너가 정상적으로 시작되면 Pod의 상태가 Running으로 변경됩니다.
status:
phase: Running
podIP: 10.244.2.15
conditions:
- type: Ready
status: "True"Code language: CSS (css)Scheduler: Pod는 어디에 배치될까?
Scheduler는 Pod를 “가장 적합한” 노드에 배치합니다. 이 과정은 Filtering과 Scoring 두 단계로 나뉩니다.
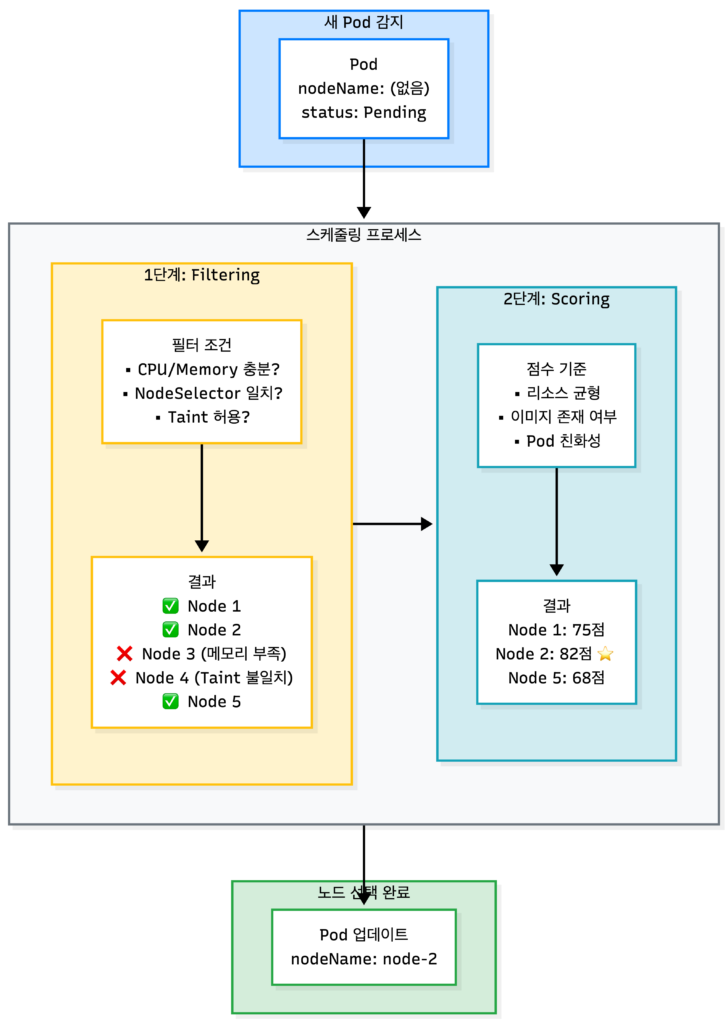
Filtering: 부적합한 노드 제외
먼저 조건에 맞지 않는 노드를 제외합니다.
| 필터 | 확인 내용 |
|---|---|
| PodFitsResources | 노드에 요청한 CPU/Memory가 충분한가? |
| NodeSelector | Pod의 nodeSelector와 노드 라벨이 일치하는가? |
| PodToleratesNodeTaints | 노드의 Taint를 Pod가 Toleration하는가? |
| NoVolumeZoneConflict | 요청한 볼륨이 이 노드의 존(zone)에서 사용 가능한가? |
예를 들어, Pod가 memory: 4Gi를 요청했는데 노드에 2Gi만 남아있다면 해당 노드는 제외됩니다.
Scoring: 최적의 노드 선택
Filtering을 통과한 노드들에 점수(0-100)를 매깁니다.
| 점수 기준 | 설명 |
|---|---|
| NodeResourcesBalancedAllocation | CPU와 Memory 사용률이 균형 잡힌 노드 선호 |
| ImageLocality | 필요한 이미지가 이미 있는 노드 선호 (Pull 시간 절약) |
| InterPodAffinity | Pod Affinity 규칙에 맞는 노드 선호 |
모든 점수를 합산해 가장 높은 점수의 노드가 선택됩니다. 동점이면 랜덤으로 선택합니다.
스케줄링에 영향을 주는 방법들
nodeSelector: 가장 간단한 방법
특정 라벨이 있는 노드에만 배치합니다.
spec:
nodeSelector:
disktype: ssd
gpu: "true"Code language: JavaScript (javascript)Node Affinity: 세밀한 제어
nodeSelector보다 유연한 조건을 지정할 수 있습니다.
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 필수 조건
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values: ["ap-northeast-2a", "ap-northeast-2c"]
preferredDuringSchedulingIgnoredDuringExecution: # 선호 조건
- weight: 100
preference:
matchExpressions:
- key: disktype
operator: In
values: ["ssd"]Code language: CSS (css)- required: 반드시 만족해야 함 (안 맞으면 스케줄링 안 됨)
- preferred: 가능하면 만족 (안 맞아도 스케줄링은 됨)
Taint와 Toleration: 노드에 제한 걸기
Taint는 노드에 “경고 표시”를 하는 것입니다. 해당 Taint를 Toleration하는 Pod만 배치될 수 있습니다.
# 노드에 Taint 추가 (GPU 전용 노드)
kubectl taint nodes gpu-node-1 gpu=true:NoScheduleCode language: PHP (php)# Pod에 Toleration 추가
spec:
tolerations:
- key: "gpu"
operator: "Equal"
value: "true"
effect: "NoSchedule"Code language: PHP (php)| Effect | 의미 |
|---|---|
| NoSchedule | Toleration 없으면 스케줄링 안 함 |
| PreferNoSchedule | 가능하면 스케줄링 안 함 (soft) |
| NoExecute | 스케줄링 안 함 + 기존 Pod도 퇴출 |
nodeSelector vs Affinity vs Taint/Toleration
방식 용도 주체 nodeSelector “이 Pod는 SSD 노드에서 실행해” Pod가 노드를 선택 Node Affinity “가능하면 zone-a에서, 필수는 아님” Pod가 노드를 선택 (유연) Taint/Toleration “이 노드는 GPU Pod 전용이야” 노드가 Pod를 제한 일반적으로 nodeSelector로 시작하고, 더 세밀한 제어가 필요하면 Affinity를, 특수 목적 노드(GPU, 고성능 등)에는 Taint/Toleration을 사용합니다.
kubelet과 컨테이너 런타임: Pod는 어떻게 실행될까?
Scheduler가 노드를 선택하면, 해당 노드의 kubelet이 실제로 Pod를 실행합니다.
kubelet의 역할
kubelet은 워커 노드의 에이전트입니다. 다음과 같은 일을 합니다:
- API Server를 감시해 자신의 노드에 배정된 Pod 확인
- 컨테이너 런타임에 Pod 생성/삭제 요청
- Pod 상태를 API Server에 보고
- 리소스 사용량 모니터링
- liveness/readiness Probe 실행
CRI: 컨테이너 런타임 인터페이스
kubelet은 컨테이너를 직접 실행하지 않습니다. 대신 CRI(Container Runtime Interface)라는 표준 인터페이스를 통해 컨테이너 런타임과 통신합니다.
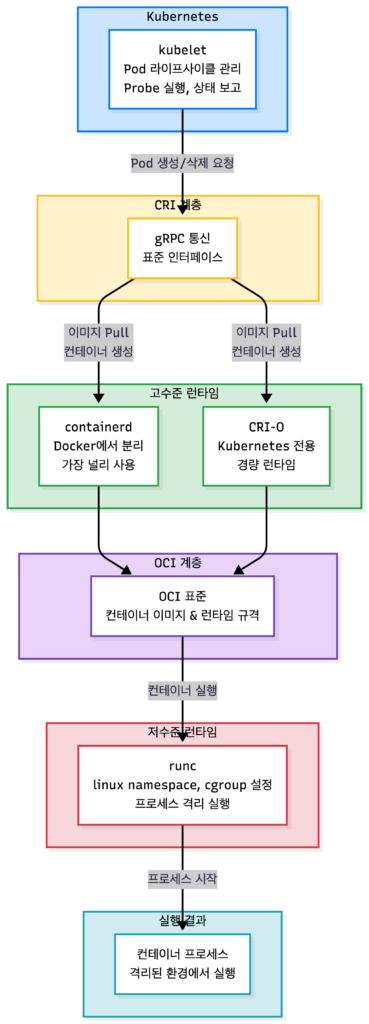
kubelet
↓ (CRI - gRPC 프로토콜)
컨테이너 런타임 (containerd, CRI-O)
↓ (OCI 표준)
저수준 런타임 (runc)
↓
실제 컨테이너 프로세스용어 정리
| 용어 | 설명 |
|---|---|
| CRI | Kubernetes가 정의한 컨테이너 런타임 표준 인터페이스 |
| gRPC | Google이 만든 원격 프로시저 호출 프레임워크. kubelet과 런타임이 이 프로토콜로 통신 |
| OCI | Open Container Initiative. 컨테이너 이미지와 런타임의 업계 표준 규격 |
| runc | OCI 표준을 구현한 저수준 런타임. Linux namespace와 cgroup을 설정해 프로세스를 격리 |
고수준 런타임 vs 저수준 런타임
| 구분 | 역할 | 예시 |
|---|---|---|
| 고수준 런타임 | 이미지 관리, 컨테이너 라이프사이클 관리, CRI 구현 | containerd, CRI-O |
| 저수준 런타임 | 실제 프로세스 격리 및 실행 (namespace, cgroup 설정) | runc |
containerd는 Docker에서 분리된 런타임으로, 현재 가장 널리 사용됩니다. CRI-O는 Kubernetes 전용으로 만들어진 경량 런타임입니다. 둘 다 내부적으로 runc를 호출해 실제 컨테이너를 실행합니다.
왜 Docker를 더 이상 직접 지원하지 않을까?
Kubernetes 1.24부터 dockershim이 제거되었습니다. Docker는 CRI를 직접 구현하지 않아서, Kubernetes가 중간 레이어(dockershim)를 유지해야 했습니다.
하지만 Docker 내부에서 사용하는 containerd는 CRI를 지원합니다. 그래서 이제는 containerd를 직접 사용합니다. Docker로 빌드한 이미지는 OCI 표준을 따르므로 여전히 잘 동작합니다. 달라진 건 런타임뿐입니다.
리소스 관리: requests와 limits
Pod가 사용할 CPU와 Memory를 지정하는 것은 안정적인 클러스터 운영의 핵심입니다.
requests vs limits
resources:
requests:
cpu: "100m" # 0.1 CPU 코어
memory: "128Mi" # 128 MiB
limits:
cpu: "500m" # 0.5 CPU 코어
memory: "512Mi" # 512 MiBCode language: PHP (php)| 구분 | requests | limits |
|---|---|---|
| 의미 | 최소 보장량 | 최대 사용량 |
| 스케줄링 | 이 값을 기준으로 노드 선택 | 스케줄링에 영향 없음 |
| CPU 초과 시 | – | Throttling (속도 제한) |
| Memory 초과 시 | – | OOMKilled (강제 종료) |
CPU 단위 이해하기
1= 1 CPU 코어100m= 0.1 코어 (m은 millicores)500m= 0.5 코어
QoS Class: 서비스 품질 등급
Kubernetes는 requests와 limits 설정에 따라 Pod에 QoS(Quality of Service) Class를 부여합니다. 이 등급은 노드 메모리가 부족할 때 어떤 Pod를 먼저 종료할지 결정합니다.
| QoS Class | 조건 | 메모리 부족 시 |
|---|---|---|
| Guaranteed | 모든 컨테이너에서 requests = limits | 가장 마지막에 종료 |
| Burstable | requests < limits (하나라도) | 중간 우선순위 |
| BestEffort | requests/limits 둘 다 없음 | 가장 먼저 종료 |
# Guaranteed 예시: requests = limits
resources:
requests:
cpu: "500m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "256Mi"Code language: PHP (php)# Burstable 예시: requests < limits
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"Code language: PHP (php)# BestEffort 예시: 아무것도 지정 안 함
resources: {}Code language: CSS (css)OOMKilled: 왜 Pod가 갑자기 죽을까?
OOMKilled는 Pod가 메모리 limit을 초과했을 때 발생합니다. 정확히 말하면, Kubernetes가 아니라 워커 노드의 Linux 커널에 있는 OOM Killer가 프로세스를 종료합니다.
컨테이너는 워커 노드의 Linux 커널 위에서 실행되기 때문에, 메모리 관리도 해당 노드의 커널이 담당합니다.
kubectl describe pod my-pod
# ...
# Last State: Terminated
# Reason: OOMKilled
# Exit Code: 137Code language: PHP (php)OOMKilled가 발생하는 경우:
- 컨테이너가 memory limit 초과: 컨테이너가 512Mi limit인데 600Mi를 쓰려고 함
- 노드 메모리 부족 (Overcommit): 여러 Pod의 requests 합은 노드 메모리 이내지만, 실제 사용량이 초과
Exit Code 137의 의미
Linux에서 시그널로 종료된 프로세스의 exit code는 128 + 시그널 번호입니다.
- 128: “시그널에 의해 종료됨”을 나타내는 기본값
- 9: SIGKILL 시그널 번호
- 137 = 128 + 9: OOM Killer가 SIGKILL로 프로세스를 강제 종료했다는 의미
참고로 Exit Code 143 = 128 + 15(SIGTERM)으로, 정상적인 종료 요청을 의미합니다.
리소스 설정 모범 사례
- 항상 requests를 설정하세요: BestEffort는 피하는 것이 좋습니다
- 실제 사용량을 모니터링한 후 limits 설정: 너무 낮으면 OOMKilled, 너무 높으면 리소스 낭비
- 중요한 Pod는 Guaranteed로: requests = limits로 설정
- Memory limits는 여유 있게: CPU는 throttling되지만, Memory는 OOMKilled됩니다
Probe: Pod가 정상인지 어떻게 확인할까?
Pod가 실행 중이라고 해서 반드시 정상인 것은 아닙니다. 애플리케이션이 멈췄거나, 아직 초기화 중일 수 있습니다. Kubernetes는 Probe를 통해 Pod 상태를 확인합니다.
세 가지 Probe
| Probe | 질문 | 실패 시 동작 |
|---|---|---|
| startupProbe | “시작 완료했어?” | 다른 Probe 실행 안 함 (시작 대기) |
| livenessProbe | “살아 있어?” | 컨테이너 재시작 |
| readinessProbe | “트래픽 받을 준비 됐어?” | Service 엔드포인트에서 제외 |
Probe 설정 예시
spec:
containers:
- name: app
image: my-app:1.0
ports:
- containerPort: 8080
# 시작 완료 확인 (느린 앱용)
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # 30번까지 실패 허용
periodSeconds: 10 # 10초마다 확인 (최대 5분)
# 살아있는지 확인
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 0 # startupProbe 성공 후 바로 시작
periodSeconds: 10 # 10초마다 확인
failureThreshold: 3 # 3번 연속 실패하면 재시작
# 트래픽 받을 준비 확인
readinessProbe:
httpGet:
path: /ready
port: 8080
periodSeconds: 5 # 5초마다 확인
failureThreshold: 3 # 3번 실패하면 Service에서 제외Code language: PHP (php)Probe 유형
# HTTP GET 방식
httpGet:
path: /healthz
port: 8080
# TCP 연결 방식
tcpSocket:
port: 3306
# 명령어 실행 방식
exec:
command:
- cat
- /tmp/healthyCode language: PHP (php)livenessProbe vs readinessProbe: 언제 뭘 써야 할까?
상황 적합한 Probe 앱이 deadlock에 빠져 응답 불가 livenessProbe (재시작 필요) DB 연결 끊김으로 일시적 장애 readinessProbe (트래픽만 차단) 초기화에 오래 걸리는 앱 startupProbe (시작 대기) 일반적으로 readinessProbe는 거의 필수, livenessProbe는 신중하게 사용합니다. livenessProbe를 잘못 설정하면 정상적인 Pod가 계속 재시작될 수 있습니다.
Spring Boot를 쓴다면 Probe API를 직접 만들 필요가 없습니다
Spring Boot Actuator는 자동으로 두 endpoint를 만들어주고, 각각 다른 체크를 수행합니다:
Endpoint 체크 내용 /actuator/health/liveness앱이 살아있는지만 확인 (단순 응답) /actuator/health/readinessDB, Redis, Kafka 등 외부 의존성 연결 상태 확인 # Spring Boot 앱의 Probe 설정 예시 livenessProbe: httpGet: path: /actuator/health/liveness port: 8080 readinessProbe: httpGet: path: /actuator/health/readiness port: 8080Code language: PHP (php)즉, Spring Boot가 알아서 liveness는 가볍게, readiness는 의존성까지 체크하도록 구분해줍니다. 커스텀 체크가 필요하면
HealthIndicator를 구현하면 됩니다.
CrashLoopBackOff: 왜 Pod가 계속 재시작될까?
kubectl get pods
# NAME READY STATUS RESTARTS AGE
# my-pod 0/1 CrashLoopBackOff 5 3mCode language: PHP (php)CrashLoopBackOff는 Pod가 반복적으로 실패하고 재시작되는 상태입니다. 원인은 보통:
- livenessProbe 실패: 헬스체크에 응답하지 않음
- 애플리케이션 크래시: exit code가 0이 아님
- OOMKilled: 메모리 초과
- 설정 오류: 환경변수 누락, 잘못된 명령어 등
Kubernetes는 재시작 간격을 점점 늘립니다 (10초 → 20초 → 40초 → … 최대 5분). 이를 exponential backoff라고 합니다.
# 원인 확인
kubectl describe pod my-pod
kubectl logs my-pod --previous # 이전 컨테이너 로그Code language: PHP (php)HPA: 트래픽에 따라 자동으로 스케일링
지금까지 Pod가 어떻게 생성되고 실행되는지 살펴봤습니다. 하지만 트래픽이 증가하면 어떻게 할까요? 수동으로 replicas를 늘릴 수도 있지만, HPA(Horizontal Pod Autoscaler)를 사용하면 자동으로 스케일링할 수 있습니다.
HPA 동작 원리
HPA는 Metrics Server에서 Pod의 리소스 사용량을 수집하고, 설정한 목표치와 비교해 replicas 수를 조정합니다.
Metrics Server → HPA → Deployment(replicas 조정) → ReplicaSet → Pod 생성/삭제Metrics Server란?
Metrics Server는 Kubernetes 클러스터의 리소스 사용량을 수집하는 공식 애드온입니다. 기본 설치에는 포함되지 않아 별도로 설치해야 합니다.
| 항목 | 설명 |
|---|---|
| 역할 | 각 노드의 kubelet에서 CPU/Memory 사용량 수집 |
| 사용처 | kubectl top, HPA, VPA |
| 설치 여부 | 기본 설치 아님, 별도 설치 필요 |
# Metrics Server 설치 확인
kubectl get pods -n kube-system | grep metrics-server
# 설치 (없으면)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 동작 확인
kubectl top nodes
kubectl top podsCode language: PHP (php)HPA 설정 예시
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # CPU 사용률 70% 유지Code language: PHP (php)위 설정은:
- CPU 사용률이 70%를 넘으면 Pod를 늘림
- CPU 사용률이 70% 미만이면 Pod를 줄임
- 최소 2개, 최대 10개 유지
# HPA 상태 확인
kubectl get hpa
# NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS
# my-app-hpa Deployment/my-app 45%/70% 2 10 3Code language: PHP (php)HPA와 Deployment replicas의 관계
HPA는 Deployment의 replicas를 직접 수정합니다. 따라서 HPA를 사용할 때는:
# HPA 사용 시 Deployment 설정
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
# replicas: 3 ← HPA가 관리하므로 생략 가능!
selector:
matchLabels:
app: my-app
template:
# ...Code language: PHP (php)| 설정 방식 | 권장 사항 |
|---|---|
| Deployment만 사용 | replicas 필수 지정 |
| HPA와 함께 사용 | replicas 생략 또는 초기값만 지정 |
HPA의 minReplicas가 실질적인 최소값이 됩니다. Deployment에 replicas: 3을 설정하고 HPA의 minReplicas: 2로 하면, HPA가 2개로 줄일 수 있습니다.
HPA가 동작하려면?
- Metrics Server가 설치되어 있어야 합니다
- Pod에 resources.requests가 설정되어 있어야 합니다
requests가 없으면 HPA가 사용률을 계산할 수 없습니다. 예를 들어
requests.cpu: 100m이고 현재 50m을 사용 중이면 사용률은 50%입니다.
VPA와의 차이
| 방식 | 이름 | 동작 |
|---|---|---|
| HPA | Horizontal Pod Autoscaler | Pod 개수를 조정 |
| VPA | Vertical Pod Autoscaler | Pod 리소스 크기를 조정 |
HPA는 수평 확장(scale out/in), VPA는 수직 확장(scale up/down)입니다. 일반적으로 HPA를 먼저 사용하고, 단일 Pod 성능이 중요한 경우 VPA를 고려합니다.
트러블슈팅 가이드
Pod가 제대로 실행되지 않을 때 확인할 포인트들입니다.
Pod 상태별 확인 사항
| 상태 | 의미 | 확인 방법 |
|---|---|---|
| Pending | 스케줄링 대기 중 | kubectl describe pod → Events 확인 |
| ContainerCreating | 컨테이너 생성 중 | 이미지 Pull 문제, 볼륨 마운트 문제 |
| CrashLoopBackOff | 반복 실패 | kubectl logs --previous |
| OOMKilled | 메모리 초과 | memory limits 증가 필요 |
| Evicted | 노드에서 퇴출 | 노드 리소스 부족 |
주요 확인 명령어
# Pod 상태 확인
kubectl get pods -o wide
# Pod 상세 정보 (Events 포함)
kubectl describe pod <pod-name>
# 컨테이너 로그
kubectl logs <pod-name>
kubectl logs <pod-name> --previous # 이전 컨테이너
# 리소스 사용량 확인
kubectl top pods
kubectl top nodes
# HPA 상태 확인
kubectl get hpaCode language: PHP (php)흔한 문제와 해결책
| 문제 | 원인 | 해결책 |
|---|---|---|
| Pod가 Pending 상태로 멈춤 | 리소스 부족 또는 nodeSelector 불일치 | 노드 추가 또는 requests 조정 |
| ImagePullBackOff | 이미지를 가져올 수 없음 | 이미지 이름, 레지스트리 인증 확인 |
| CrashLoopBackOff | 앱 크래시 또는 Probe 실패 | 로그 확인, Probe 설정 점검 |
| OOMKilled 반복 | memory limit 부족 | limits 증가 또는 메모리 누수 확인 |
마무리
이 글에서는 Kubernetes에서 Pod가 어떻게 생성되고 실행되는지 살펴봤습니다.
핵심 흐름:
kubectl apply→ API Server → etcd 저장- Scheduler가 Filtering → Scoring으로 노드 선택
- kubelet이 CRI를 통해 컨테이너 런타임에 요청
- 컨테이너 런타임이 실제 컨테이너 실행
- CNI 플러그인이 네트워크 설정
기억해야 할 것들:
- requests는 스케줄링 기준, limits는 최대 사용량
- QoS Class에 따라 메모리 부족 시 종료 우선순위가 달라짐
- livenessProbe는 재시작, readinessProbe는 트래픽 차단
- HPA로 트래픽에 따라 자동 스케일링 가능