EC2를 띄웠는데, 서버가 죽으면 어떻게 알지?
이전 글에서 t3.micro에 Ubuntu를 올리고 Docker Compose로 WordPress와 MySQL을 띄웠습니다. 블로그가 잘 돌아가고 있는 것 같긴 한데, 문득 이런 생각이 듭니다.
“CPU가 100%를 찍으면? 디스크가 꽉 차면? 내가 모르는 사이에 서버가 멈춰버리면?”
온프레미스 서버라면 모니터링 도구를 직접 설치해야 하지만, AWS는 다릅니다. EC2를 생성하는 순간부터 기본적인 모니터링이 자동으로 시작됩니다. 이 글에서는 EC2 모니터링 탭과 CloudWatch를 활용해 서버 상태를 확인하고, 문제가 생기면 알람을 받는 방법까지 다룹니다.
EC2 모니터링 탭 살펴보기
EC2 인스턴스를 선택하면 하단에 모니터링 탭이 있습니다. 별도 설정 없이도 AWS가 자동으로 수집하는 메트릭들을 바로 확인할 수 있습니다.
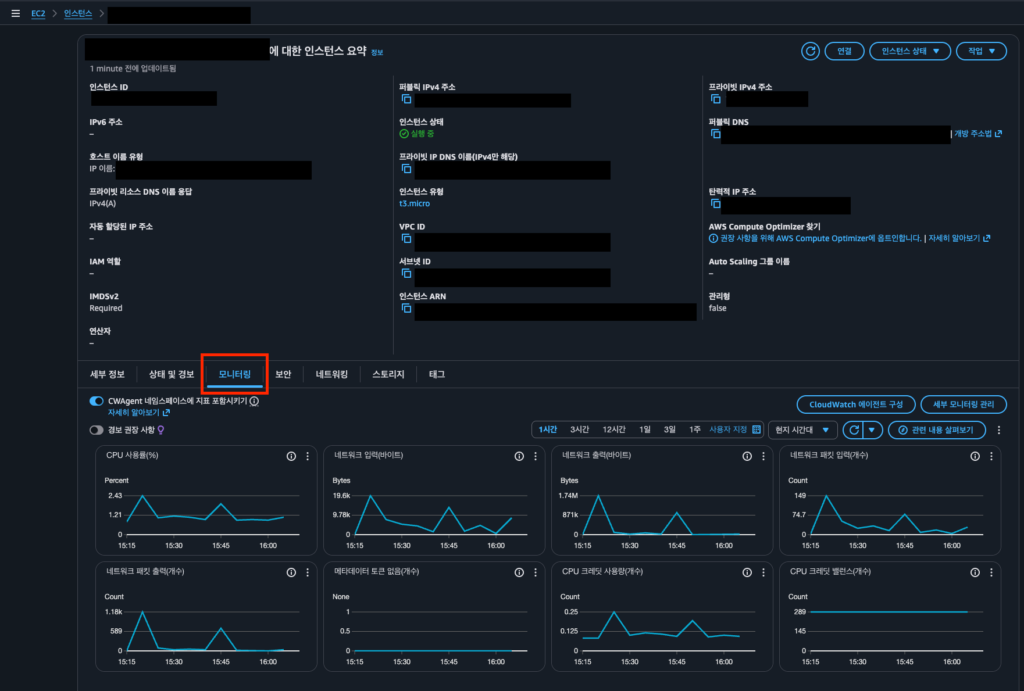
기본 제공 메트릭
| 메트릭 | 설명 |
|---|---|
| CPU 사용률 (CPUUtilization) | 인스턴스의 CPU 사용 비율 |
| 네트워크 입력/출력 (NetworkIn/Out) | 네트워크 트래픽 바이트 수 |
| 디스크 읽기/쓰기 (DiskReadOps/WriteOps) | 디스크 I/O 작업 수 |
| 디스크 읽기/쓰기 바이트 | 디스크 I/O 데이터량 |
| 상태 검사 (StatusCheckFailed) | 인스턴스 및 시스템 상태 |
기본 모니터링은 5분 간격으로 데이터를 수집하며, 추가 비용 없이 사용할 수 있습니다.
💡 디스크 I/O와 디스크 용량은 다릅니다
기본 제공되는 “디스크 읽기/쓰기”는 읽기/쓰기 작업량입니다. “100GB 중 80GB 사용 중” 같은 디스크 용량 정보는 기본 모니터링에서 제공하지 않습니다. 디스크 용량과 메모리 사용률을 보려면 CloudWatch Agent를 설치해야 하는데, 이 내용은 Part 2에서 다룹니다.
기본 모니터링 vs 세부 모니터링
모니터링 탭에서 세부 모니터링 관리 버튼을 보셨을 겁니다. 이 버튼을 클릭하면 “추가 요금이 적용됩니다”라는 경고가 나타납니다.
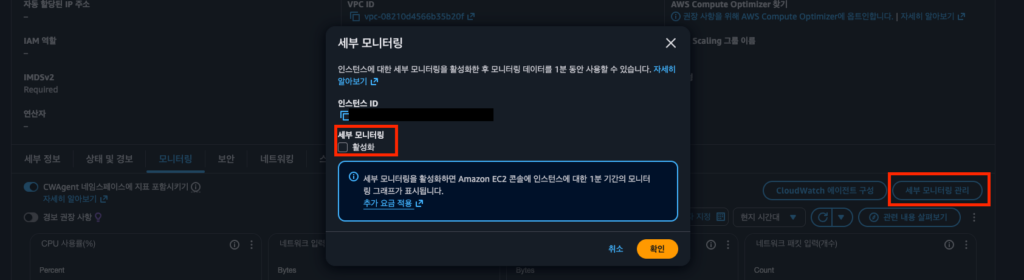
두 모니터링의 차이
| 구분 | 기본 모니터링 | 세부 모니터링 |
|---|---|---|
| 데이터 수집 주기 | 5분 | 1분 |
| 비용 | 무료 | 유료 |
| 활성화 방식 | 기본값 (자동) | 수동 활성화 필요 |
| 수집하는 메트릭 종류 | CPU, 네트워크, 디스크 I/O 등 | 동일 |
핵심을 정리하면, 세부 모니터링은 “더 많은 정보”를 주는 게 아니라 “같은 정보를 더 자주(1분 간격으로)” 수집하는 것입니다. (AWS 공식 문서)
세부 모니터링 비용 계산
세부 모니터링을 활성화하면 기본 메트릭이 커스텀 메트릭 요금으로 과금됩니다. (CloudWatch 요금 페이지)
- EC2 인스턴스당 기본 메트릭: 약 7개
- 메트릭당 비용: $0.30/월 (처음 10,000개 기준)
- t3.micro 1대 기준: 7 × $0.30 = 약 $2.10/월
💡 세부 모니터링이 필요한 경우
실시간 트래픽 대응이 필요한 프로덕션 환경, Auto Scaling을 사용하는 경우에는 1분 간격의 세부 모니터링이 유용합니다. 하지만 개인 블로그나 개발 서버라면 5분 간격의 기본 모니터링으로 충분합니다.
CloudWatch란?
EC2 모니터링 탭에서 본 그래프들은 사실 Amazon CloudWatch라는 서비스에서 가져온 것입니다. CloudWatch는 AWS의 통합 모니터링 플랫폼으로, 단순히 데이터를 보여주는 것 이상의 기능을 제공합니다.
CloudWatch의 핵심 기능
| 기능 | 설명 |
|---|---|
| 메트릭 수집 | AWS 서비스들의 성능 데이터를 자동 수집 |
| 대시보드 | 여러 메트릭을 한 화면에서 시각화 |
| 알람 | 임계값 초과 시 알림 발송 또는 자동 조치 |
| 로그 관리 | 애플리케이션 로그 중앙 수집 및 분석 |
EC2 모니터링 구조 이해하기
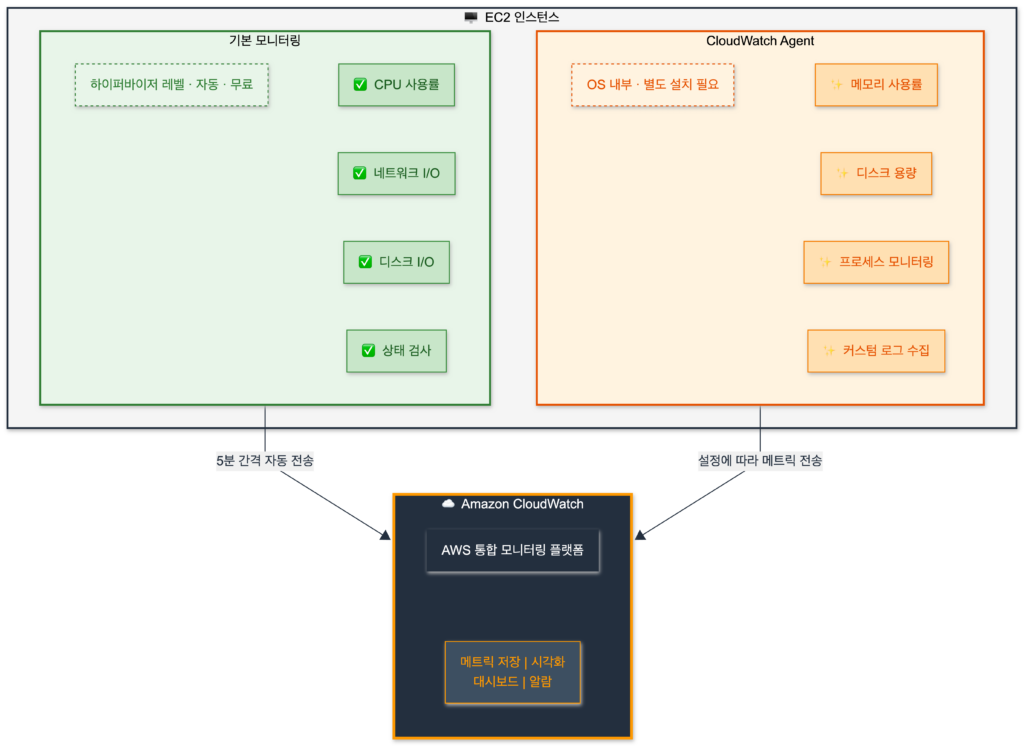
기본 모니터링 메트릭은 AWS 인프라(하이퍼바이저) 레벨에서 수집됩니다. 그래서 OS 내부 정보인 메모리 사용률이나 디스크 용량은 기본 제공되지 않습니다. 이 정보를 수집하려면 인스턴스 안에 CloudWatch Agent를 설치해야 합니다.
💡 CloudWatch Agent는 Part 2에서 다룹니다
이번 글에서는 먼저 기본 모니터링과 CloudWatch 콘솔 사용법을 익히고, Agent 설치는 다음 글에서 상세히 다루겠습니다.
CloudWatch 무료 범위 알아보기
“CloudWatch 쓰면 돈 나가는 거 아니야?”라는 걱정이 들 수 있습니다. 다행히 CloudWatch는 꽤 넉넉한 Free Tier를 제공합니다. (CloudWatch 요금 페이지)
CloudWatch Free Tier (영구 무료)
| 항목 | 무료 제공량 | 설명 | 비고 |
|---|---|---|---|
| 기본 모니터링 메트릭 | 무제한 | EC2, S3 등 AWS 서비스 기본 메트릭 | – |
| 커스텀 메트릭 | 10개/월 | 사용자 정의 메트릭 | Agent 설치 시 사용 |
| 알람 | 10개 | 표준 해상도 알람 | – |
| 대시보드 | 3개 | 각 50개 메트릭까지 | – |
| API 요청 | 100만 건/월 | GetMetricStatistics 등 | – |
| 로그 수집 | 5GB/월 | 월간 총 수집량 기준, 초과 시 $0.50/GB | Agent 설치 시 사용 |
| 로그 저장 | 5GB/월 | 월간 저장량 기준, 초과 시 $0.03/GB | Agent 설치 시 사용 |
t3.micro 하나로 개인 블로그를 운영하는 수준이라면, 무료 범위 안에서 충분히 모니터링할 수 있습니다.
💡 로그 Free Tier 상세 설명
“5GB 수집, 5GB 저장”은 월간 총량 기준입니다. 예를 들어 하루에 200MB씩 로그를 보내면 한 달에 약 6GB가 되어 1GB 초과분에 대해 $0.50가 과금됩니다. 5GB가 넘으면 자동 삭제되는 게 아니라 초과분에 대해 요금이 부과됩니다. 로그 보존 기간은 별도로 설정해야 하며, 설정하지 않으면 무기한 저장되어 저장 비용이 계속 쌓입니다.
💡 비용이 발생하는 경우
세부 모니터링 활성화, CloudWatch Agent로 커스텀 메트릭 추가(11개 이상), 10개 초과 알람 생성 등의 경우에 비용이 발생합니다. 하지만 소규모 운영에서는 대부분 무료 범위 내에서 해결됩니다.
CloudWatch 콘솔에서 메트릭 확인하기
이제 CloudWatch 콘솔에서 직접 EC2 메트릭을 확인해보겠습니다.
CloudWatch 콘솔 접속
- AWS 콘솔 상단 검색창에 CloudWatch 입력
- CloudWatch 서비스 클릭
EC2 메트릭 찾기
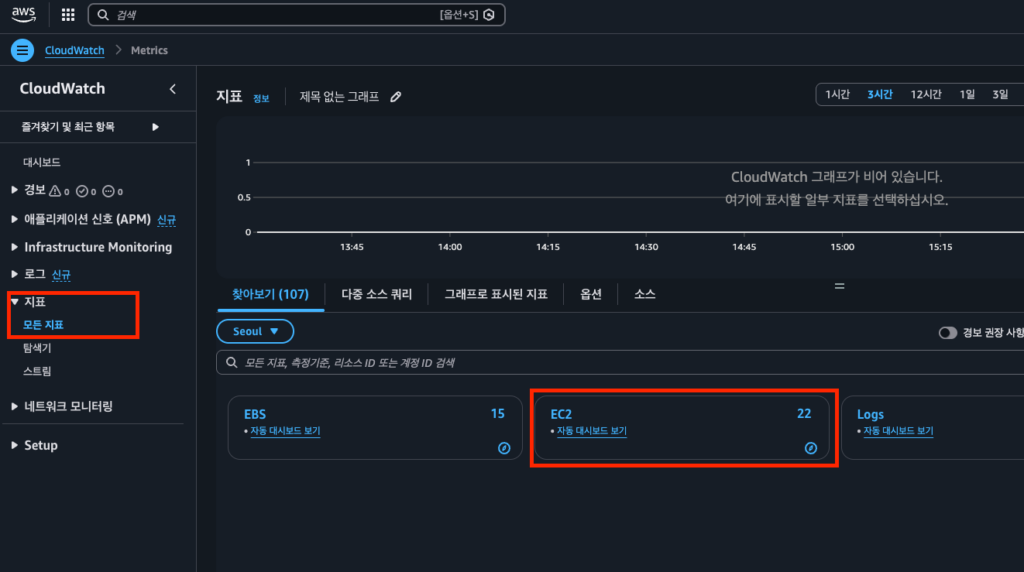
- 좌측 메뉴에서 지표(Metrics) > 모든 지표 클릭
- 하단의 AWS 네임스페이스에서 EC2 선택
- 인스턴스별 지표 클릭
CPU 사용률 그래프 보기
- 검색창에 인스턴스 ID 입력 (EC2 콘솔에서 확인 가능)
- CPUUtilization 메트릭 체크박스 선택
- 상단에 그래프가 표시됩니다
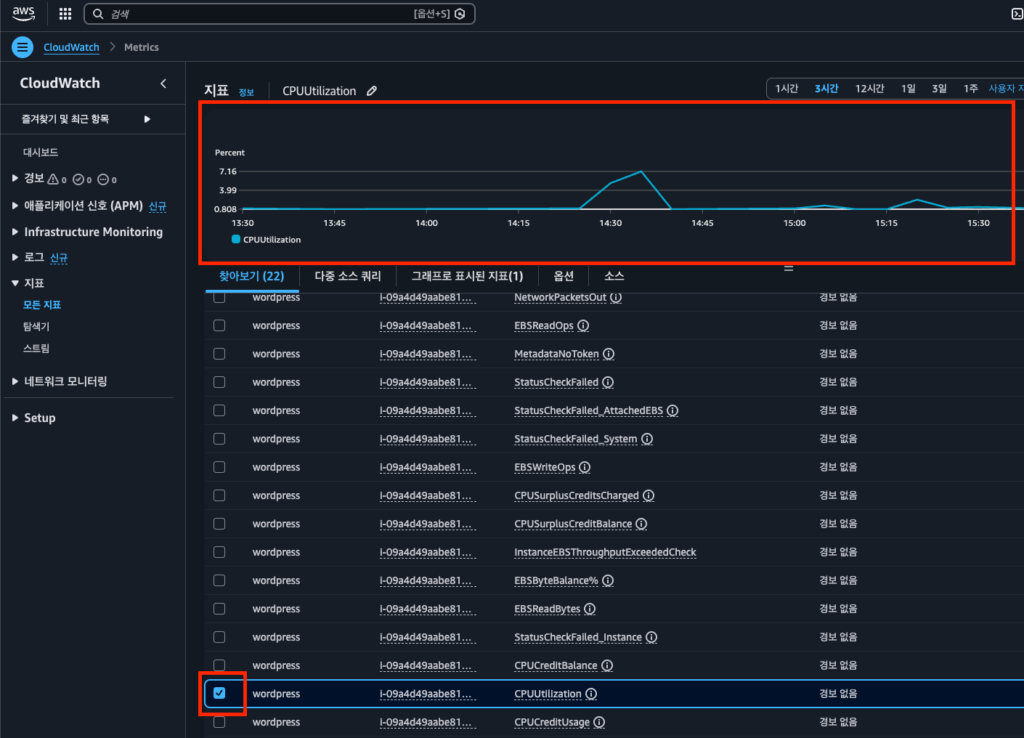
그래프 상단의 시간 범위를 조절하면 1시간, 3시간, 12시간, 1일, 1주일 등 원하는 기간의 데이터를 볼 수 있습니다.
💡 여러 메트릭을 한 번에 보려면?
여러 메트릭의 체크박스를 동시에 선택하면 하나의 그래프에 여러 지표가 표시됩니다. 네트워크 입출력을 함께 보거나, 여러 인스턴스의 CPU를 비교할 때 유용합니다.
CPU 사용률 알람 만들기
모니터링의 핵심은 문제가 생겼을 때 즉시 알 수 있는 것입니다. CloudWatch 알람을 설정하면 CPU가 80%를 넘을 때 이메일로 알림을 받을 수 있습니다.
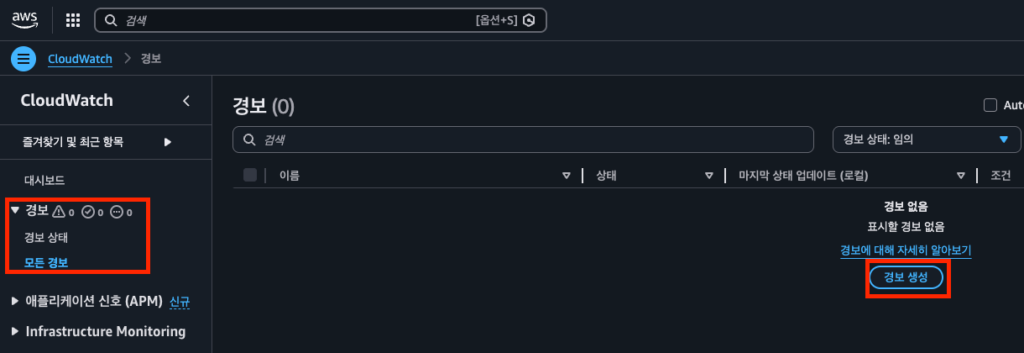
1단계: 알람 생성 시작
- CloudWatch 좌측 메뉴에서 경보(Alarms) > 모든 경보 클릭
- 경보 생성 버튼 클릭
- 지표 선택 클릭
2단계: 메트릭 선택
- EC2 > 인스턴스별 지표 선택
- 모니터링할 인스턴스의 CPUUtilization 선택
- 지표 선택 버튼 클릭
3단계: 조건 설정
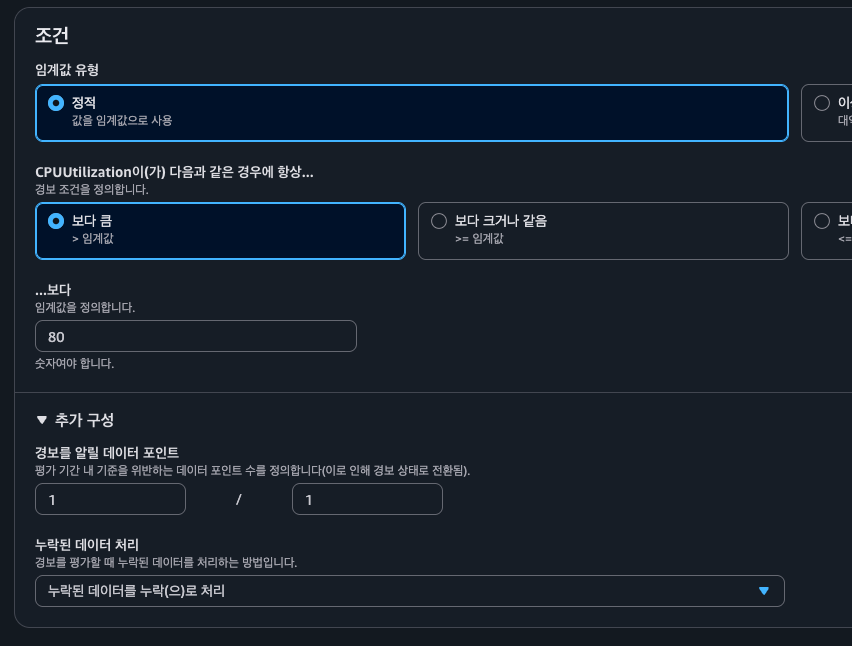
| 설정 항목 | 권장 값 | 설명 |
|---|---|---|
| 임계값 유형 | 정적 | 고정된 값으로 비교 |
| 조건 | 보다 큼 | 임계값 초과 시 알람 |
| 임계값 | 80 | CPU 80% 초과 시 |
| 데이터 포인트 | 1/1 | 1회 초과 시 바로 알람 |
💡 데이터 포인트 설정 팁
“1/1″은 1번 측정에서 1번 초과하면 바로 알람입니다. 일시적인 스파이크에도 알람이 올 수 있습니다. “3/5″로 설정하면 5번 측정 중 3번 초과해야 알람이 발생해서 노이즈를 줄일 수 있습니다.
4단계: 알림 설정 (SNS 연동)
알람이 발생했을 때 이메일을 받으려면 SNS(Simple Notification Service) 주제를 생성해야 합니다.
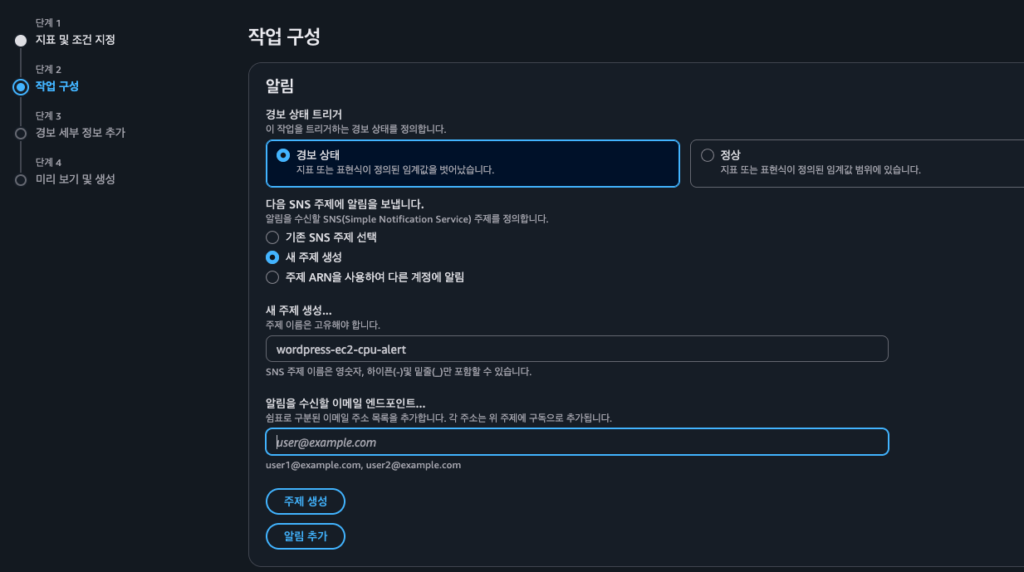
- 알람 상태 트리거: “경보 상태”(In alarm) 선택
- SNS 주제 선택: “새 주제 생성” 선택
- 주제 이름:
ec2-cpu-alert입력 - 알림을 받을 이메일: 본인 이메일 입력
⚠️ 이메일 구독 확인 필수!
SNS 주제를 생성하면 입력한 이메일로 구독 확인 메일이 발송됩니다. 메일을 열어 Confirm subscription 링크를 클릭해야 알림을 받을 수 있습니다. 스팸함도 확인해보세요.
5단계: 알람 이름 지정 및 생성
- 알람 이름:
EC2-CPU-High-Alert(알아보기 쉬운 이름) - 알람 설명: “EC2 CPU 사용률 80% 초과 알람” (선택사항)
- 다음 > 경보 생성 클릭
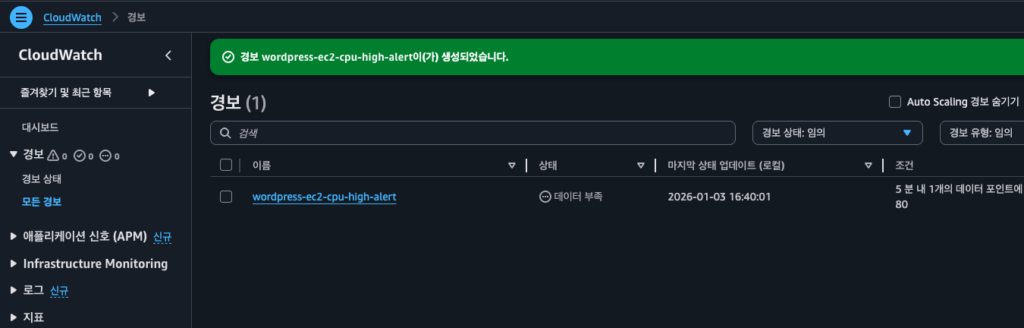
생성이 완료되면 알람 목록에서 확인할 수 있습니다. 현재 CPU가 80% 이하라면 상태가 “OK”로 표시됩니다.
알람 테스트하기
실제로 알람이 작동하는지 확인하고 싶다면, EC2에 SSH 접속 후 CPU 부하를 발생시켜볼 수 있습니다.
# CPU 부하 발생 (테스트 후 Ctrl+C로 중지)
yes > /dev/null &
yes > /dev/null &
# 부하 중지
killall yesCode language: PHP (php)💡 yes와 killall 명령어 설명
yes: “y”를 무한 반복 출력하는 명령어입니다.> /dev/null로 출력을 버리면 CPU만 계속 사용하게 됩니다.&를 붙이면 백그라운드에서 실행됩니다.killall yes: 실행 중인 모든yes프로세스를 종료합니다.killall은 프로세스 이름으로 종료하는 명령어입니다.- t3.micro는 vCPU가 2개이므로
yes를 2개 실행하면 CPU 100%에 가깝게 올라갑니다.
잠시 후 이메일로 알람 알림이 도착하면 정상적으로 설정된 것입니다.
기본 모니터링의 한계
여기까지 따라오셨다면 EC2 기본 모니터링과 CloudWatch 알람 설정을 완료하신 겁니다. 하지만 실제 서버 운영에서 가장 궁금한 정보는 따로 있을 수 있습니다.
기본 모니터링으로 볼 수 없는 것들
| 필요한 정보 | 기본 제공 여부 | 해결 방법 |
|---|---|---|
| 메모리 사용률 | ❌ | CloudWatch Agent |
| 디스크 용량 (남은 공간) | ❌ | CloudWatch Agent |
| 특정 프로세스 상태 | ❌ | CloudWatch Agent |
| 애플리케이션 로그 | ❌ | CloudWatch Agent |
기본 모니터링은 AWS 하이퍼바이저 레벨에서 데이터를 수집하기 때문에, OS 내부 정보는 제공하지 않습니다. 메모리가 부족해서 서버가 느려지거나, 디스크가 꽉 차서 로그를 못 쓰는 상황은 기본 모니터링만으로는 감지할 수 없습니다.
💡 다음 글 예고: CloudWatch Agent로 메모리/디스크 모니터링하기
Part 2에서는 CloudWatch Agent를 Ubuntu EC2에 설치하고, 메모리 사용률과 디스크 용량을 모니터링하는 방법을 다룹니다. 메모리 80% 초과 알람까지 설정해보겠습니다.
정리
이 글에서 다룬 내용을 정리합니다.
EC2 기본 모니터링은 인스턴스 생성과 동시에 자동으로 시작되며, CPU 사용률, 네트워크 I/O, 디스크 I/O, 상태 검사 메트릭을 5분 간격으로 무료 제공합니다.
세부 모니터링은 같은 메트릭을 1분 간격으로 수집하며, 메트릭당 $0.30/월의 비용이 발생합니다. 개인 블로그나 개발 서버에서는 기본 모니터링으로 충분합니다.
CloudWatch는 AWS의 통합 모니터링 플랫폼으로, 메트릭 시각화, 대시보드, 알람 기능을 제공합니다. Free Tier로 10개 알람, 3개 대시보드까지 무료로 사용할 수 있습니다.
CloudWatch 알람을 설정하면 CPU 같은 메트릭이 임계값을 초과할 때 이메일로 알림을 받을 수 있습니다. SNS 주제를 생성하고 이메일 구독을 확인해야 합니다.
메모리와 디스크 용량은 기본 모니터링에서 제공하지 않습니다. CloudWatch Agent를 설치해야 하며, 이 내용은 Part 2에서 다룹니다.