들어가며
이전 글에서는 외부 사용자의 요청이 어떻게 Kubernetes 클러스터 내부의 Pod까지 도달하는지 살펴봤습니다. 외부 LB → NodePort → Ingress Controller → Service → Pod 으로 이어지는 흐름이었죠.
그런데 한 가지 의문이 남습니다. 클러스터 내부에서 Pod끼리는 어떻게 통신할까요? 예를 들어, 주문 서비스 Pod이 사용자 서비스 Pod의 API를 호출할 때 실제로 어떤 일이 벌어질까요?
이 글에서는 다음 질문들에 답합니다.
- Pod IP(10.244.x.x 같은)는 누가 할당하는 걸까?
- 같은 노드에 있는 Pod끼리는 어떻게 통신할까?
- 다른 노드에 있는 Pod끼리는?
- Cilium, Calico 같은 CNI 플러그인은 정확히 뭘 하는 걸까?
curl http://user-service.svc처럼 Service 이름으로 요청하면 어떻게 IP를 찾는 걸까?
전체 그림: Pod 네트워크의 구성 요소
본격적으로 들어가기 전에, Pod 간 통신에 관여하는 주요 컴포넌트들을 먼저 정리하겠습니다.
| 컴포넌트 | 역할 | 비유 |
|---|---|---|
| CNI 플러그인 | Pod 네트워크 구성, IP 할당 | 도로를 깔아주는 것 |
| kube-proxy | Service → Pod 라우팅 (iptables/IPVS 사용) | 도로 위의 이정표 |
| CoreDNS | Service 이름 → ClusterIP 변환 | 전화번호부 |
CNI와 kube-proxy는 역할이 다릅니다
이 둘을 혼동하기 쉬운데, 명확히 구분해야 합니다:
- CNI 플러그인: “Pod A와 Pod B가 통신할 수 있는 네트워크 자체를 만들어줄게”
- kube-proxy: “Service IP로 요청하면 실제 Pod IP로 바꿔줄게”
CNI가 없으면 Pod 간 통신 자체가 불가능하고, kube-proxy가 없으면 Service를 통한 접근이 불가능합니다.
참고로 IPVS(IP Virtual Server)는 kube-proxy가 사용할 수 있는 또 다른 모드입니다. iptables보다 대규모 클러스터에서 성능이 좋습니다.
Pod IP는 누가 할당할까?
kubectl get pods -o wide를 실행하면 각 Pod에 IP가 할당되어 있는 것을 볼 수 있습니다.
NAME READY STATUS IP NODE
user-app-7d4b8c6f5-abc12 1/1 Running 10.244.1.15 worker-1
order-app-5f6a9d8e2-xyz34 1/1 Running 10.244.2.23 worker-2이 10.244.x.x 같은 IP는 어디서 오는 걸까요? 답은 CNI(Container Network Interface) 플러그인입니다.
CNI란 무엇인가?
CNI는 컨테이너 네트워크를 구성하기 위한 표준 인터페이스입니다. CNCF(Cloud Native Computing Foundation) 프로젝트로, Kubernetes뿐 아니라 다양한 컨테이너 런타임에서 사용됩니다.
핵심은 이겁니다: Kubernetes는 자체 네트워크 구현을 제공하지 않습니다. 대신 CNI라는 표준 인터페이스를 정의하고, 실제 구현은 플러그인(Cilium, Calico, Flannel 등)에게 맡깁니다.
Pod 생성 시 네트워크 설정 흐름
Pod가 생성될 때 네트워크는 어떻게 설정될까요? Kubernetes 공식 문서를 참고하면 다음과 같은 흐름으로 진행됩니다:
1. API Server → kubelet: "이 노드에 Pod 생성해"
2. kubelet → 컨테이너 런타임: "새 네트워크 네임스페이스 만들어"
3. 컨테이너 런타임 → CNI 플러그인: "ADD 명령 실행" (네트워크 설정 요청)
4. CNI 플러그인:
- 네트워크 인터페이스 생성 (veth pair)
- IP 주소 할당 (IPAM)
- 라우팅 규칙 설정
5. CNI 플러그인 → 컨테이너 런타임: "설정 완료, IP는 10.244.1.15야"
6. 컨테이너 런타임 → kubelet: "네트워크 준비 완료"
7. kubelet: 컨테이너 시작Code language: JavaScript (javascript)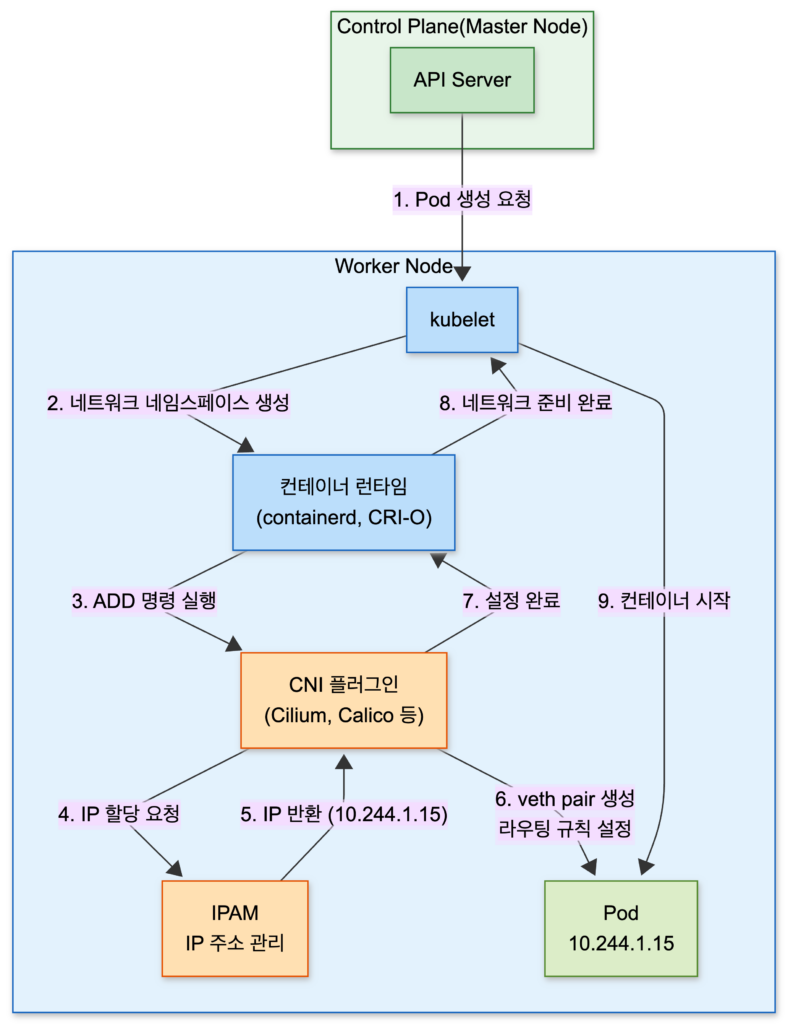
CNI 플러그인은 /opt/cni/bin/ 디렉토리에 실행 파일로 존재하고, 설정은 /etc/cni/net.d/에 JSON 형태로 저장됩니다.
CIDR 대역과 노드별 IP 할당
Pod IP는 보통 노드별로 다른 대역을 사용합니다. 여기서 CIDR(Classless Inter-Domain Routing)은 IP 주소 범위를 표현하는 방식입니다. /16, /24 같은 숫자는 네트워크 주소의 비트 수를 의미합니다.
클러스터 Pod CIDR: 10.244.0.0/16 (전체 Pod 네트워크)
├── worker-1: 10.244.1.0/24 (이 노드의 Pod들은 10.244.1.x)
├── worker-2: 10.244.2.0/24 (이 노드의 Pod들은 10.244.2.x)
└── worker-3: 10.244.3.0/24 (이 노드의 Pod들은 10.244.3.x)이렇게 노드별로 서브넷을 나누면 “10.244.2.x IP는 worker-2에 있다”는 것을 라우팅 테이블만으로 알 수 있어서, 다른 노드로 패킷을 전달할 때 효율적입니다.
IPAM(IP Address Management)이란?
CNI 플러그인 내부에는 IPAM이라는 컴포넌트가 있습니다. Pod에 IP를 할당하고 관리하는 역할을 합니다. 어떤 IP가 사용 중인지 추적하고, 새 Pod에 사용 가능한 IP를 배정합니다.
같은 노드 내 Pod 간 통신
이제 실제 통신 과정을 살펴보겠습니다. 먼저 같은 노드에 있는 Pod끼리 통신하는 경우입니다.

veth pair: 가상 네트워크 케이블
Pod는 자체 네트워크 네임스페이스를 가집니다. 이건 Pod가 독립된 네트워크 환경을 갖는다는 의미입니다. 그렇다면 이 격리된 Pod가 호스트(노드)와 어떻게 연결될까요?
답은 veth(Virtual Ethernet) pair입니다. veth pair는 가상의 네트워크 케이블처럼 동작합니다. 한쪽 끝은 Pod 안에, 다른 쪽 끝은 호스트에 연결됩니다.
각 Pod마다 독립된 veth pair가 생성됩니다. Pod A는 자신만의 veth pair(veth-a)로, Pod B는 자신만의 veth pair(veth-b)로 Bridge에 연결됩니다. 같은 노드에 있더라도 각 Pod는 별도의 “케이블”을 갖는 셈입니다.
구조를 간단히 설명하면:
| 계층 | 구성 요소 | 설명 |
|---|---|---|
| Pod 내부 | eth0 (veth 한쪽 끝) | Pod의 네트워크 인터페이스 |
| 연결 | veth pair | Pod와 호스트를 연결하는 가상 케이블 |
| 호스트 | Linux Bridge (cbr0) | Pod들을 연결하는 가상 스위치 |
Linux Bridge: Pod들의 스위치
Linux Bridge(보통 cbr0 또는 cni0라는 이름)는 같은 노드에 있는 Pod들을 연결하는 가상 스위치 역할을 합니다. 물리적인 네트워크 스위치처럼, 연결된 장치들 사이에서 패킷을 전달합니다.
패킷 흐름 추적
Pod A(10.244.1.15)가 같은 노드의 Pod B(10.244.1.20)에게 패킷을 보내는 과정:
- Pod A 내부: 애플리케이션이 10.244.1.20으로 패킷 전송
- Pod A → veth: 패킷이 Pod의 eth0(veth의 한쪽 끝)으로 나감
- veth → Bridge: veth의 다른 쪽 끝이 연결된 Linux Bridge(cbr0)로 전달
- Bridge 내부: Bridge가 MAC 주소 테이블을 참조해 Pod B의 veth로 전달
- veth → Pod B: Pod B의 eth0으로 패킷 도착
이 과정은 모두 노드 내부에서 일어나므로, 물리 네트워크를 거치지 않아 매우 빠릅니다.
확인해보기: veth pair 직접 보기
노드에 SSH 접속해서 다음 명령어로 확인할 수 있습니다:
# 노드의 네트워크 인터페이스 확인 ip link show type veth # Bridge에 연결된 인터페이스 확인 brctl show cbr0Code language: PHP (php)
다른 노드 간 Pod 통신
이제 다른 노드에 있는 Pod끼리 통신하는 경우를 살펴보겠습니다. 이 부분이 CNI 플러그인마다 구현이 다른 핵심 영역입니다.

문제: Pod IP는 클러스터 내부에서만 의미가 있다
Pod A(10.244.1.15, worker-1)가 Pod B(10.244.2.23, worker-2)에게 패킷을 보내려고 합니다. 문제는 10.244.2.23이라는 IP는 물리 네트워크에서 알 수 없는 주소라는 점입니다.
일반적인 네트워크 장비(라우터, 스위치)는 10.244.x.x 같은 Pod 네트워크 대역을 모릅니다. 그래서 CNI 플러그인이 이 문제를 해결해야 합니다.
해결책 1: Overlay 네트워크 (VXLAN)
Overlay 네트워크는 기존 물리 네트워크 위에 가상의 네트워크 레이어를 올리는 방식입니다. 대표적인 기술이 VXLAN(Virtual Extensible LAN)입니다.
Pod A (10.244.1.15) → Pod B (10.244.2.23)로 패킷을 전송할 때:
원본 패킷:
| 필드 | 값 |
|---|---|
| 출발지 (src) | 10.244.1.15 (Pod A) |
| 목적지 (dst) | 10.244.2.23 (Pod B) |
| 내용 | [데이터] |
VXLAN 캡슐화 후:
| 레이어 | 출발지 | 목적지 |
|---|---|---|
| 외부 헤더 (노드 IP) | 192.168.1.10 (worker-1) | 192.168.1.20 (worker-2) |
| 내부 원본 (Pod IP) | 10.244.1.15 (Pod A) | 10.244.2.23 (Pod B) |
VXLAN은 Pod 간 패킷을 UDP로 감싸서 노드 간에 전달합니다. 받는 쪽 노드에서 캡슐화를 풀고 원래 패킷을 목적지 Pod로 전달합니다.
장점: 기존 물리 네트워크를 수정할 필요 없음 단점: 캡슐화/역캡슐화 오버헤드 발생
해결책 2: Direct Routing (BGP)
Direct Routing은 물리 네트워크의 라우팅 테이블에 Pod 네트워크 경로를 직접 추가하는 방식입니다. 주로 BGP(Border Gateway Protocol)를 사용합니다. BGP는 대규모 네트워크에서 라우팅 정보를 교환하는 표준 프로토콜입니다.
각 노드의 라우팅 테이블:
worker-1:
10.244.1.0/24 → 로컬 (이 노드의 Pod들)
10.244.2.0/24 → 192.168.1.20 (worker-2로 보내)
10.244.3.0/24 → 192.168.1.30 (worker-3으로 보내)
worker-2:
10.244.1.0/24 → 192.168.1.10 (worker-1로 보내)
10.244.2.0/24 → 로컬
10.244.3.0/24 → 192.168.1.30 (worker-3으로 보내)BGP를 사용하면 이 라우팅 정보를 노드들끼리 자동으로 공유하고 업데이트합니다.
장점: 캡슐화 오버헤드 없음, 더 나은 성능
단점: 네트워크 환경에 따라 설정이 복잡할 수 있음
Overlay vs Underlay(Direct Routing)
구분 Overlay (VXLAN) Underlay (BGP) 동작 방식 패킷 캡슐화 라우팅 테이블 직접 설정 물리 네트워크 요구사항 없음 (UDP만 통과하면 됨) L3 연결 필요, BGP 지원 성능 캡슐화 오버헤드 있음 더 빠름 설정 난이도 쉬움 네트워크 환경에 따라 다름 대표 CNI Flannel (VXLAN 모드) Calico (BGP 모드)
CNI 플러그인 비교: Flannel → Calico → Cilium
이제 실제로 많이 사용되는 CNI 플러그인들을 비교해보겠습니다. CNI의 발전 과정을 이해하면 각 플러그인의 특징이 더 명확해집니다.
Flannel: 단순함의 대명사
Flannel은 가장 단순한 CNI 플러그인 중 하나입니다. CoreOS(현재 Red Hat)에서 개발했으며, “Pod 간 통신만 되면 된다”는 철학으로 설계되었습니다.
특징:
- VXLAN 기반 Overlay 네트워크 (기본)
- 설치와 설정이 매우 간단
- 경량, 리소스 사용량 적음
한계:
- NetworkPolicy 미지원: Pod 간 트래픽 제어 불가
- 암호화 미지원
- 고급 기능 없음
NetworkPolicy란?
NetworkPolicy는 Pod 간 트래픽을 제어하는 방화벽 규칙입니다. 예를 들어:
- “frontend Pod는 backend Pod에만 접근 가능”
- “database Pod는 backend Pod에서만 접근 가능”
- “외부에서 들어오는 트래픽은 80포트만 허용”
보안이 중요한 프로덕션 환경에서는 필수적인 기능입니다. Flannel은 이 기능을 지원하지 않아서, 별도의 NetworkPolicy 솔루션(Calico 등)을 함께 사용하거나 다른 CNI를 선택해야 합니다.
# Flannel 설치
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.ymlCode language: PHP (php)Flannel은 학습용이나 간단한 테스트 환경에 적합합니다. 프로덕션에서는 NetworkPolicy가 필요한 경우가 많아 다른 CNI를 선택하게 됩니다.
Calico: 프로덕션 표준
Calico는 Tigera에서 개발한 CNI로, 네트워크 성능과 보안을 모두 잡은 프로덕션 환경의 표준입니다.
특징:
- BGP 기반 Direct Routing (기본) 또는 VXLAN 선택 가능
- NetworkPolicy 완벽 지원: Pod 간 트래픽 제어
- 대규모 클러스터에서 검증된 성능
- 온프레미스, 클라우드, 하이브리드 환경 모두 지원
한계:
- Cilium 대비 Observability 기능 부족
- 암호화(WireGuard)는 수동 설정 필요
# Calico 설치
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.0/manifests/calico.yamlCode language: PHP (php)Calico는 “프로덕션에서 무난하게 쓸 수 있는” 선택지입니다. NetworkPolicy가 필요하고, 특별히 Cilium의 고급 기능이 필요하지 않다면 Calico가 좋은 선택입니다.
Cilium: eBPF 기반의 미래
Cilium은 eBPF(extended Berkeley Packet Filter) 기술을 기반으로 한 최신 CNI입니다. Linux 커널 레벨에서 네트워킹을 처리해 높은 성능과 풍부한 기능을 제공합니다.
특징:
- eBPF 기반: iptables 대신 커널 레벨에서 직접 패킷 처리
- kube-proxy 대체 가능: Service 라우팅까지 eBPF로 처리
- L7(애플리케이션 레이어) NetworkPolicy 지원
- Hubble: 강력한 네트워크 Observability 도구 내장
- 투명한 암호화 (WireGuard)
한계:
- 다른 CNI 대비 리소스 사용량 높음
- 최신 Linux 커널 필요 (eBPF 지원)
# Cilium 설치 (Helm 사용)
helm install cilium cilium/cilium --namespace kube-systemCode language: PHP (php)왜 어떤 클러스터에는 kube-proxy가 없을까?
Cilium은 kube-proxy의 역할(Service → Pod 라우팅)까지 eBPF로 대체할 수 있습니다. 그래서 Cilium을 사용하는 클러스터에서는 kube-proxy DaemonSet이 없는 경우가 많습니다. eBPF가 iptables보다 효율적이기 때문에, 대규모 클러스터에서 성능 이점이 있습니다.
eBPF와 노드 간 전송은 별개의 내용입니다
Cilium의 핵심인 eBPF는 “패킷 처리 엔진”이지, “노드 간 전송 방식”이 아닙니다.
Cilium도 노드 간 통신에는 Flannel, Calico처럼 Overlay(VXLAN) 또는 Native Routing 중 하나를 선택합니다.
레이어 역할 Cilium의 선택 패킷 처리 어떻게 패킷을 처리할까? eBPF (iptables 대신) 노드 간 전송 어떻게 다른 노드로 보낼까? VXLAN 또는 Native Routing 즉, Cilium은 eBPF로 패킷을 빠르게 처리하면서, 노드 간 전송은 환경에 맞게 Overlay나 Direct Routing을 선택할 수 있습니다.
CNI 비교 정리
| 구분 | Flannel | Calico | Cilium |
|---|---|---|---|
| 기반 기술 | VXLAN | BGP / VXLAN | eBPF |
| NetworkPolicy | ❌ 미지원 | ✅ L3/L4 지원 | ✅ L3/L4/L7 지원 |
| kube-proxy 대체 | ❌ | ❌ | ✅ |
| Observability | ❌ | 기본적 | ✅ Hubble |
| 암호화 | ❌ | 수동 설정 | ✅ 내장 |
| 리소스 사용량 | 낮음 | 중간 | 높음 |
| 추천 환경 | 학습, 테스트 | 프로덕션 (범용) | 프로덕션 (고급 기능 필요 시) |
어떤 CNI를 선택해야 할까?
- 입문/테스트: Flannel (단순함)
- 프로덕션 (일반): Calico (검증된 안정성)
- 프로덕션 (고급 보안/관측성 필요): Cilium (최신 기술)
클라우드 환경에서는 클라우드 제공자의 CNI(AWS VPC CNI, Azure CNI 등)를 사용하는 경우도 많습니다.
서비스 디스커버리: 도메인으로 Pod 찾기
지금까지 Pod IP를 직접 사용하는 통신을 살펴봤습니다. 하지만 실제로는 Pod IP를 직접 쓰는 경우는 거의 없습니다. 왜냐하면 Pod IP는 언제든 바뀔 수 있기 때문입니다.
대신 우리는 Service 이름을 사용합니다:
# Pod 내부에서 (user-service는 K8s Service 이름)
curl http://user-service.svc:8080/api/usersCode language: PHP (php)이 user-service.svc라는 이름은 어떻게 IP로 변환될까요? 바로 CoreDNS가 담당합니다.
CoreDNS의 역할
CoreDNS는 Kubernetes의 기본 DNS 서버입니다. 모든 Service와 Pod에 대한 DNS 레코드를 관리합니다.
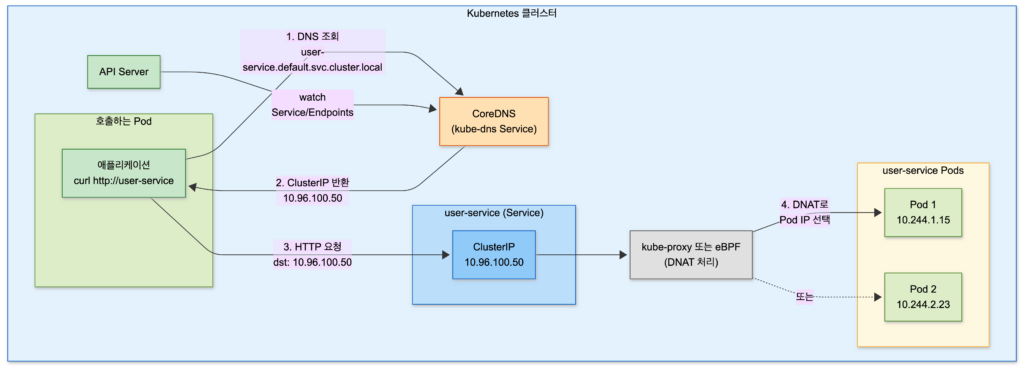
CoreDNS는 다음과 같이 동작합니다:
- API Server Watch: CoreDNS는 Kubernetes API Server를 watch하면서 Service, Endpoints 변경을 감지
- DNS 레코드 생성: 변경 감지 시 해당 Service의 DNS 레코드를 동적으로 생성
- 쿼리 응답: Pod에서 DNS 쿼리가 오면 해당 Service의 ClusterIP 반환
Service 도메인 구조
Kubernetes에서 Service의 전체 도메인(FQDN)은 다음 형식입니다:
<service-name>.<namespace>.svc.cluster.localCode language: CSS (css)예를 들어:
user-service.default.svc.cluster.localorder-service.production.svc.cluster.local
같은 네임스페이스면 짧은 이름으로 충분
모든 Pod의 /etc/resolv.conf에는 search 도메인이 설정되어 있습니다:
# Pod 내부에서 cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5Code language: PHP (php)search 줄의 의미: DNS 조회 시 짧은 이름 뒤에 자동으로 붙여서 시도할 도메인 목록입니다.
예를 들어 curl http://user-service를 실행하면, 시스템은 다음 순서로 DNS 조회를 시도합니다:
1. user-service.default.svc.cluster.local → 성공하면 여기서 끝!
2. user-service.svc.cluster.local → (1번 실패 시)
3. user-service.cluster.local → (2번 실패 시)
4. user-service → (모두 실패 시 외부 DNS로)Code language: CSS (css)즉, user-service만 입력해도 시스템이 알아서 .default.svc.cluster.local을 붙여서 시도합니다. 이것이 같은 네임스페이스에서 짧은 이름만 써도 되는 이유입니다.
ndots:5의 의미: “이름에 점(.)이 5개 미만이면 search 도메인을 먼저 시도해”
user-service(점 0개) → search 도메인 먼저 시도api.example.com(점 2개) → search 도메인 먼저 시도a.b.c.d.e.f(점 5개 이상) → 바로 외부 DNS로
이 search 도메인 덕분에, 같은 네임스페이스 내에서는 짧은 이름만 써도 됩니다:
# 같은 네임스페이스(default)에서
curl http://user-service # → user-service.default.svc.cluster.local
# 다른 네임스페이스의 Service
curl http://user-service.production # → user-service.production.svc.cluster.localCode language: PHP (php)외부 도메인 vs Service 도메인: 트래픽 흐름 비교
같은 클러스터 내에서 통신할 때, 외부 도메인과 Service 도메인은 완전히 다른 경로를 거칩니다.
외부 도메인 사용 시 (api.example.com):
Pod → CoreDNS → 외부 DNS → 공인 IP 획득
→ 외부 LB → Ingress Node → Ingress Controller
→ Service → 대상 PodService 도메인 사용 시 (user-service):
Pod → CoreDNS → ClusterIP 획득 (10.96.100.50)
→ kube-proxy/eBPF가 ClusterIP를 Pod IP로 변환
→ 대상 Pod왜 Service 도메인을 쓰면 더 효율적인가?
외부 도메인을 사용하면 트래픽이 클러스터 밖으로 나갔다가 다시 들어옵니다. 네트워크 홉이 많아지고, Ingress Controller를 거치면서 불필요한 처리가 발생합니다.
Service 도메인을 사용하면 트래픽이 클러스터 내부에서만 흐릅니다. 네트워크 홉이 적고, 직접 Pod 간 통신이 가능해 훨씬 빠릅니다.
비교 외부 도메인 Service 도메인 경로 클러스터 외부 경유 클러스터 내부에서 완료 네트워크 홉 많음 적음 지연 시간 높음 낮음 Ingress 부하 발생 없음
Headless Service: Pod IP 직접 얻기
일반적인 Service(ClusterIP)를 DNS 조회하면 Service의 ClusterIP가 반환됩니다. 하지만 때로는 개별 Pod의 IP가 필요한 경우가 있습니다(예: StatefulSet의 각 인스턴스에 직접 접근).
이때 사용하는 것이 Headless Service입니다:
apiVersion: v1
kind: Service
metadata:
name: my-headless-service
spec:
clusterIP: None # 이 설정이 Headless Service를 만듦
selector:
app: my-appCode language: PHP (php)Headless Service를 DNS 조회하면 ClusterIP 대신 모든 Pod의 IP 목록이 반환됩니다:
# 일반 Service
nslookup user-service
# → 10.96.100.50 (ClusterIP)
# Headless Service
nslookup my-headless-service
# → 10.244.1.15, 10.244.2.23, 10.244.3.31 (Pod IPs)Code language: CSS (css)실전 트러블슈팅
Pod 간 통신이 안 될 때 어디를 봐야 할까요? 단계별 체크리스트입니다.
1. DNS 문제 확인
# Pod 내부에서 DNS 조회 테스트
kubectl exec -it <pod-name> -- nslookup user-service
kubectl exec -it <pod-name> -- nslookup kubernetes.default
# CoreDNS Pod 상태 확인
kubectl get pods -n kube-system -l k8s-app=kube-dns
# CoreDNS 로그 확인
kubectl logs -n kube-system -l k8s-app=kube-dnsCode language: PHP (php)2. 네트워크 연결 확인
# Pod에서 다른 Pod로 직접 통신 테스트
kubectl exec -it <pod-name> -- ping <target-pod-ip>
kubectl exec -it <pod-name> -- curl <target-pod-ip>:<port>
# Service를 통한 통신 테스트
kubectl exec -it <pod-name> -- curl <service-name>:<port>Code language: HTML, XML (xml)3. CNI 플러그인 상태 확인
# CNI 플러그인 Pod 상태 (예: Cilium)
kubectl get pods -n kube-system -l k8s-app=cilium
# CNI 로그 확인
kubectl logs -n kube-system -l k8s-app=ciliumCode language: PHP (php)4. 흔한 문제와 해결책
| 증상 | 가능한 원인 | 확인 방법 |
|---|---|---|
| DNS 조회 실패 | CoreDNS가 죽어있음 | kubectl get pods -n kube-system -l k8s-app=kube-dns |
| 같은 노드 Pod 통신 불가 | CNI 플러그인 문제 | CNI Pod 로그 확인 |
| 다른 노드 Pod 통신 불가 | 노드 간 네트워크 문제, CNI 설정 | 노드 간 ping 테스트, CNI 설정 확인 |
| Service 접근 불가 | kube-proxy 문제, Endpoints 없음 | kubectl get endpoints <service-name> |
결론
이 글에서 살펴본 내용을 정리하면:
- CNI 플러그인이 Pod 네트워크를 구성하고 IP를 할당합니다.
- 같은 노드 Pod 간 통신은 veth pair와 Linux Bridge를 통해 이루어집니다.
- 다른 노드 Pod 간 통신은 Overlay(VXLAN) 또는 Direct Routing(BGP)으로 처리됩니다.
- Flannel → Calico → Cilium 순으로 기능이 풍부해지며, 환경에 맞게 선택합니다.
- CoreDNS가 Service 이름을 IP로 변환하는 서비스 디스커버리를 담당합니다.
- Service 도메인을 사용하면 클러스터 내부에서 효율적으로 통신할 수 있습니다.
Pod 간 통신의 전체 흐름을 이해하면, 네트워크 문제가 발생했을 때 어디를 봐야 할지 명확해집니다. CNI가 문제인지, DNS가 문제인지, 아니면 Service 설정이 문제인지 구분할 수 있게 되죠.